Week of November 20th

“Climb🧗♀️ in the back with your head👤 in the Clouds☁️☁️… And you’re gone”
Hi All –
Happy Name Your PC💻 Day!
“Forward yesterday makes me wanna stay…”
“Welcome back, to that same old place that you laughed 😂 about”. So, after a short recess we made our splendiferous return this week. To where else? …But to no other than Google Cloud Platform a.k.a GCP☁️ , of course! 😊 So after completing our three-part Cloud Journey, we were feeling the need for a little refresher… Also, there were still had a few loose ends we needed to sew🧵 up. The wonderful folks at Google Cloud☁️ put together amazing compilation on GCP☁️ through their Google Cloud Certified Associate Cloud Engineer Path but we were feeling the need for a little more coverage on GCP CLI i.e. “gcloud”, “gsutil”, and “bq” . In addition, we had a great zest to learn a little more about some of the service offerings like GCP Development Services and APIs. Fortunately, we knew exactly who could deliver tremendous content on GCP☁️ as well as hit the sweet spot on some of the areas where we felt we were lacking a bit. That would be of course one of our favorite Canucks 🇨🇦 Mattias Andersson
For those who are not familiar with Mattias, he is one of the legendary instructors on A Cloud Guru. Mattias is especially well-known for his critically acclaimed Google Certified Associate Cloud Engineer 2020 course.
In this brilliantly produced course Mattias delivers the goods and then some! The goal of the course is to prepare those interested in preparing for Google’s Associate Cloud Engineer (ACE) Certification exam but it’s structured in a manner to efficiently to provide you with the skills to troubleshoot GCP through having a better understanding of “Data flows”. Throughout the course Mattias emphasizes the “see one, do one, teach one” technique in order to get the best ROI out of the tutorial.
So, after some warm salutations and a great overview of the ACE Exam, Mattias takes right to an introductions of all the Google Cloud product and Services. He accentuates the importance of Data Flow in fully understanding how all GCP solutions work. “Data Flow is taking data or information and it’s moving it around, processing it and remembering it.”
Data flows – are the foundation of every system
- Moving, Processing, Remembering
- Not just Network, Compute, Storage
- Build mental models
- Helps you make predictions
- Identify and think through data flows
- Highlights potential issues
- Requirement and options not always clear
- Especially in the real world🌎
- Critical skills for both real world🌎 and exam📝 questions
“Let’s get it started, in here…And the base keep runnin’ 🏃♂️ runnin’ 🏃♂️, and runnin’ 🏃♂️ runnin’ 🏃♂️, and runnin’ 🏃♂️ runnin’ 🏃♂️, and runnin’ 🏃♂️ runnin’ 🏃♂️, and runnin’ 🏃♂️ runnin’ 🏃♂️, and runnin’ 🏃♂️ runnin’ 🏃♂️, and runnin’ 🏃♂️ runnin’ 🏃♂️, and runnin’ 🏃♂️ runnin’ 🏃♂️, and…”
After walking🚶♀️ us through how to create a Free account it was time ⏰ to kick off 🦵 us with a little Billing and Billing Export.
“Share it fairly, but don’t take a slice of my pie 🥧”
Billing Export –to BigQuery enables you to export your daily usage and cost estimates automatically throughout the day to a BigQuery dataset.
- Export must be set up per billing account
- Resources should be placed into appropriate projects
- Resources should be tagged with labels🏷
- Billing export is not real-time
- Delay is hours
Billing IAM – Role: Billing Account User
- Link🔗 projects to billing accounts
- Restrictive permissions
- Along with the Project Creator allow a user to create new projects linked to billing
Budgets – Help with project planning and controlling costs
- Setting a budget lets you track spend
- Apply budget to billing account or a Project
Alerts 🔔 – notify billing administrators when spending exceeds a percentage of your budget
Google Cloud Shell 🐚 – provides with CLI access to Cloud☁️ Resources directly from your browser.
- Command-line tool🔧 to interact GCP☁️
- Basic Syntax
gcloud–project=myprojid compute instances list
gcloud compute instances create myvm
gcloud services list --available
gsutil ls
gsutil mb -l northamerica-northeast1 gs://storage-lab-cli
gsutil label set bucketlables.json gs://storage-lab-cli
GCS via gsutil in Command Line
gcloud config list gcloud config set project igneous-visitor-293922 gsutil ls gsutil ls gs://storage-lab-console-088/ gsutil ls gs://storage-lab-console-088/** gsutil mb --help gsutil mb -l northamerica-northeast1 gs://storage-lab-cli-088 gsutil label get gs://storage-lab-console-088/ gsutil label get gs://storage-lab-console-088/ > bucketlabels.json cat bucketlabels.json gsutil label get gs://storage-lab-cli-088 gsutil label set bucketlabels.json gs://storage-lab-cli-088 gsutil label ch -l "extralable:etravalue" gs://storage-lab-cli-088 gsutil versioning get gs://storage-lab-cli-088 gsutil versioning set on gs://storage-lab-cli-088 gsutil versioning get gs://storage-lab-cli-088 gsutil cp README-Cloudshell.txt gs://storage-lab-cli-088 gsutil ls -a gs://storage-lab-cli-088 gsutil rm gs://storage-lab-cli-088/README-Cloudshell.txt gsutil cp gs://storage-lab-console-088/** gs://storage-lab-cli-088/ gsutil acl ch -u AllUsers:R gs://storage-lab-cli-088/shutterstock.jpg
Create VM via gsutil in Command Line
gcloud config get-value project gcloud compute instances list gcloud services list gcloud services list --enabled gcloud services list --help gcloud services list –available gcloud services list --available |grep compute gcloud services -h gcloud compute instances create myvm gcloud compute instances delete myvm
Security🔒 Concepts
Confidentiality, Integrity, and Availability (CIA)
- You cannot view data you shouldn’t
- You cannot change data you shouldn’t
- You can access data you should
Authentication, Authorization, Accounting (AIA)
- Authentication – Who are you?
- Authorization – What are you allowed to do?
- Accounting – What did you do?
- Resiliency – Keep it running 🏃♂️
- Security🔒 Products
- Security🔒 Features
- Security🔒 Mindset
- Includes Availability Mindset
Key🔑 Security🔒 Mindset (Principles)
- Least privilege
- Defense in depth
- Fail Securely
Key🔑 Security🔒 Products/Features
- Identity hierarchy👑 (Google Groups)
- Resource⚙️ hierarchy👑 (Organization, Folders📂, Projects)
- Identity and Access Management (IAM)
- Permissions
- Roles
- Bindings
- GCS ACLs
- Billing management
- Networking structure & restrictions
- Audit / Activity Logs (provided by Stackdriver)
- Billing export
- To BigQuery
- To file (in GCS bucket🗑)
- Can be JSON or CSV format
- GCS object Lifecycle Management
IAM – Resource Hierarchy👑
- Resource⚙️
- Something you create in GCP☁️
- Project
- Container for a set of related resources
- Folder📂
- Contains any number of Projects and Subfolders📂
- Organization
- Tied to G Suite or Cloud☁️ Identity domain
IAM – Permissions & Roles
Permissions – allows you to a perform a certain action
- Each one follows the form Service.Resource.Verb
- Usually correspond to REST API methods
- pubsub.subcription.consume
- pubsub.topics.publish
Roles – is a collection of permissions to use or manage GCP☁️ resources
- Primitive Roles – Project-level and often too broad
- Viewer is read-only
- Editor can view and change things
- Owner can also control access & billing
- Predefined Roles
- roles/bigquery.dataEditor, roles/pub.subscriber
- Read through the list of roles for each product! Think about why each exists
- Custom Role – Project or Org-Level collection you define of granular permissions
IAM – Members & Groups
Members – some Google-known identity
- Each member is identifying by unique email📧 address
- Can be:
- user: Specific Google account
- G Suite, Cloud☁️ Identity, gmail, or validated email
- serviceAccount: Service account for apps/services
- group: Google group of users and services accounts
- domain: whole domain managed by G Suite or Cloud☁️ Identity
- allAuthenticatedUsers: Any Google account or service account
- allUsers: Anyone on the internet (Public)
- user: Specific Google account
Groups – a collection of Google accounts and service accounts
- Every group has a unique email📧 address that is associated with the group
- You never act as the group
- But membership in a group can grant capabilities to individuals
- Use them for everything
- Can be used for owner when within an organization
- Can nest groups in an organization
- One group for each department, all those in group for all staff
IAM – Policies
Policies – binds members to roles for some scope of resources
- Enforce who can do what to which thing(s)
- Attached to some level in the Resource⚙️ history
- Organization
- Folder📂
- Project Resource⚙️
- Roles and Members listed in policy, but Resources identified by attachment
- Always additive (Allow) and never subtractive (no Deny)
- One policy per Resource⚙️
- Max 1500-member binding per policy
gCloud[GROUP] add-iam-policy-binding [Resource-NAME] --role [ROLE-ID-TO-GRANT] –member user: [USER-EMAIL] gCloud[GROUP] remove-iam-policy-binding [Resource-NAME] --role [ROLE-ID-TO-REVOKE] –member user: [USER-EMAIL]
Billing Accounts – represents some way to pay for GCP☁️ service usuage
- Type of Resource⚙️ that lives outside of Projects
- Can belong to an Organization
- Inherits Org-level IAM policies
- Can be linked to projects
- Not the Owner
- No impact on project IAM
- Not the Owner
| Role | Purpose | Scope |
| Billing Account Creator | Create new self-service billing accounts | Org |
| Billing Account Administrator | Manage billing accounts | Billing Account |
| Billing Account User | Link Projects to billing accounts | Billing Account |
| Billing Account Viewer | View billing account cost information and transactions | Billing Account |
| Project Billing Manager | Link/unlink the project to/from a billing account | Project |
Monthly Invoiced Billing – Billed monthly and pay by invoice due date
- Pay via check or wire transfer
- Increase project and quota limits
- Billing administrator of org’s current billing account contacts Cloud☁️ Billing Support
- To Determine eligibility
- To apply to switch to monthly invoicing
- Eligibility depends on
- Account age
- Typical monthly spend
- Country
Networking
Choose the right solution to get data to the right Resource⚙️
- Latency reduction – Use Servers physically close to clients
- Load Balancing – Separate from auto-scaling
- System design – Different servers may handle different parts of the system
- Cross-Region Load Balancing – with Global🌎 Anycast IPs
- Cloud☁️ Load Balancer 🏋️♀️ – all types; internal and external
- HTTP(S) Load Balancer 🏋️♀️ (With URL Map)
Unicast vs Anycast
Unicast – There is only one unique device in the world that can handle this; send it there.
Anycast – There are multiple devices that could handle this; send it to anyone – but ideally the closest.
Load Balancing – Layer 4 vs Layer 7
- TCP is usually called Layer 4 (L4)
- HTTP and HTTPS work at Layer (L7)
- Each layer is built on the one below it
- To route based on URL paths, routing needs to understand L7
- L4 cannot route based on the URL paths defined in L7
DNS – Name resolution (via the Domain Name System) can be the first step in routing
- Some known issues with DNS
- Layer 4 – Cannot route L4 based on L7s URL paths
- Chunky – DNS queries often cached and reused for huge client sets
- Sticky – DNS lookup “locks on” and refreshing per request has high cost
- Extra latency because each request includes another round-trip
- More money for additional DNS request processing
- Not Robust – Relies on the client always doing the right thing
- Premium tier routing with Global🌎 anycast Ips avoids these problems
Options for Data from one Resource to another
- VPC (Global🌎) Virtual Private Cloud☁️ – Private SDN space in GCP☁️
- Not just Resource-to-Resource – also manages the doors to outside & peers
- Subnets (regional) – create logical spaces to contain resources
- All Subnets can reach all others – Globally without any need for VPNs
- Routes (Global🌎) define “next hop” for traffic🚦 based on destination IP
- Routes are Global🌎 and apply by Instance-level Tags, not by Subnet
- No route to the Internet gateway means no such data can flow
- Firewall🔥 Rules (Global🌎) further filter data flow that would otherwise route
- All FW Rules are Global🌎 and apply by Instance-level Tags or Service Acct.
- Default Firewall🔥 Rules are restrictive inbound and permissive outbound
IPs and CIDRS
- IP Address is 255.255.255.255 (dotted quad) where each piece is 0-255
- CIDR block is group of IP addresses specified in <IP>/xy notation
- Turn IP address into 32-bit binary number
- 10.10.0.254 -> 00001010 00001010 00000000 11111110
- /xy in CIDR notation locks highest (leftmost) bits in IP address (0-32)
- abc.efg.hij.klm/32 is single IP address (255.255.255.255) because all 32 bits are looked
- abc.efg.hij.klm /24 is 24 is 256 (255.555.255.0) IP addresses because last 8 bits can vary
- 0.0.0.0/0 means “any IP address” because no bits are locked
- RFC1918 defines private (i.e non-internet) address ranges you can use:
- 10.0.0.0/8 172.16.0.12, and 192.168.0.0/16
Subnet CIDR Ranges
- You can edit a subnet to increase its CIDR range
- No need to recreate subnet or instances
- New range must contain old range (i.e. old range must be subnet)
Shared VPC
- In an Organization, you can share VPCs among multiple projects
- Host Project: One project owns the Shared VPC
- Service Projects: Other projects granted access to use all/part of Shared VPC
- Lets multiple projects coexist on same local network (private IP space)
- Let’s a centralized team manage network security🔒
“Ride, captain👨🏿✈️ ride upon your mystery ship⛵️“
GKE
A Kubernetes ☸️ cluster is a set of nodes that run containerized applications. Containerizing applications packages an app with its dependences and some necessary services.
K8s ☸️ you know that the control plane consists of the kube-apiserver, kube-scheduler, kube-controller-manager and an etcd datastore.
Deploy and manage clusters on-prem
Step 1: The container runtime
Step 2: Installing kubeadm
Step 3: Starting the Kubernetes cluster ☸️
Step 4: Joining a node to the Kubernetes cluster ☸️
Deploy and manage clusters on-prem in the Cloud☁️
To deploy and manage your containerized applications and other workloads on your Google Kubernetes Engine (GKE) cluster, you use the K8s ☸️ system to create K8s ☸️ controller objects. These controller objects represent the applications, daemons, and batch jobs running 🏃♂️ on your clusters.
Cloud Native Application Properties
- Use Cloud☁️ platform services.
- Scale horizontally.
- Scale automatically, using proactive and reactive actions.
- Handle node and transient failures without degrading.
- Feature non-blocking asynchronous communication in a loosely coupled architecture.
Kubernetes fits into the Cloud-native ecosystem
K8s ☸️ native technologies (tools/systems/interfaces) are those that are primarily designed and built for Kubernetes ☸️.
- They don’t support any other container or infrastructure orchestration systems
- K8s ☸️ accommodative technologies are those that embrace multiple orchestration mechanisms, K8s ☸️ being one of them.
- They generally existed in pre-Kubernetes☸️ era and then added support for K8s ☸️ in their design.
- Non-Kubernetes ☸️ technologies are Cloud☁️ native but don’t support K8s ☸️.
Deploy and manage applications on Kubernetes ☸️
K8s ☸️ deployments can be managed via Kubernetes ☸️ command line interface kubectl. Kubectl uses the Kubernetes ☸️ API to interact with the cluster.
When creating a deployment, you will need to specify the container image for your application and the number of replicas that you need in your cluster.
- Create Application
- create the application we will be deploying to our cluster
- Create a Docker🐳 container image
- create an image that will contain the app built.
- Create a K8s ☸️ Deployment
- K8s ☸️ deployments are responsible for creating and managing pods
- K8s ☸️ pod is a group of one or more containers, tied together for the purpose of administration and networking.
- K8s ☸️ Deployments can be created in two ways
- kubectl run command
- YAML configuration
Declarative Management of Kubernetes☸️ Objects Using Configuration Files
K8s ☸️ objects can be created, updated, and deleted by storing multiple object configuration files in a directory and using kubectl apply to recursively create and update those objects as needed.
This method retains writes made to live objects without merging the changes back into the object configuration files. kubectl diff also gives you a preview of what changes apply will make.
DaemonSet
A DaemonSet ensures that all (or some) Nodes run a copy of a Pod. As nodes are added to the cluster, Pods are added to them. As nodes are removed from the cluster, those Pods are garbage collected. Deleting a DaemonSet will clean up the Pods it created.
Some typical uses of a DaemonSet are:
- Running 🏃♂️ a cluster storage🗄 daemon on every node
- Running 🏃♂️ a logs collection daemon on every node
- Running 🏃♂️ a node monitoring🎛 daemon on every node
Cloud Load Balancer 🏋️♀️ that GKE created
Google Kubernetes☸️ Engine (GKE) offers integrated support for two types of Cloud☁️ Load Balancing for a publicly accessible application:
When you specify type:LoadBalancer 🏋️♀️ in the Resource⚙️ manifest:
- GKE creates a Service of type LoadBalancer 🏋️♀️. GKE makes appropriate Google Cloud API calls to create either an external network load balancer 🏋️♀️ or an internal TCP/UDP load balancer 🏋️♀️.
- GKE creates an internal TCP/UDP load balancer 🏋️♀️ when you add the Cloud.google.com/load-balancer 🏋️♀️-type: “Internal” annotation; otherwise, GKE creates an external network load balancer 🏋️♀️.
Although you can use either of these types of load balancers 🏋️♀️ for HTTP(S) traffic🚦, they operate in OSI layers 3/4 and are not aware of HTTP connections or individual HTTP requests and responses.
Imagine all the people👥 sharing all the world🌎
GCP Services
Compute
Compute Engine (GCE) – (Zonal) (IaaS) – Fast-booting Virtual Machines (VMs) for rent/demand
- Pick set machine type – standard, high memory, high CPU-or custom CPU/RAM
- Pay by the second (60 second min.) for CPUs, RAM
- Automatically cheaper if you keep running 🏃♂️ it (“sustained use discount”)
- Even cheaper for “preemptible” or long-term use commitment in a region
- Can add GPUs and paid OSes for extra cost*
- Live Migration: Google seamlessly moves instance across hosts, as needed
Kubernetes Engine (GKE) – (Regional (IaaS/Paas) -Managed Kubernetes ☸️ cluster for running 🏃♂️ Docker🐳 containers (with autoscaling)
- Kubernetes☸️ DNS on by default for service discovery
- NO IAM integration (unlike AWS ECS)
- Integrates with Persistent Disk for storage
- Pay for underlying GCE instances
- Production cluster should have 3+ nodes*
- No GKE management fee, no matter how many nodes in cluster
App Engine (GAE) – (Regional (PaaS) that takes your code and runs it
- Much more than just compute – Integrates storage, queues, NoSQL
- Flex mode (“App Engine Flex”) can run any container & access VPC
- Auto-Scales⚖️ based on load
- Standard (non-Flex) mode can turn off las instance when no traffic🚦
- Effectively pay for underlying GCE instances and other services
Cloud Functions – (Regional (FaaS), “Serverless” -Managed K8s☸️ cluster for running 🏃♂️ Docker🐳 containers (with autoscaling)
- Runs code in response to an event – Node.js Python🐍, Java☕️, Go🟢
- Pay for CPU and RAM assigned to function, per 100ms (min. 100ms)
- Each function automatically gets an HTTP endpoint
- Can be triggered by GCS objects, Pub/Sub messages, etc.
- Massively Scalable⚖️ (horizontally) – Runs🏃♂️ many copies when needed
Storage
Persistent Disk (PD) – (Zonal) Flexible🧘♀️, block-based🧱 network-attached storage; boot disk for every GCE instance
- Perf Scales⚖️ with volume size; max way below Local SSD, but still plenty fast🏃♂️
- Persistent disks persist, and are replicated (zone or region) for durability
- Can resize while in use (up to 64TB), but will need file system update with VM
- Snapshots (and machine images🖼 ) add even more capability and flexibility
- Not file based NAS, but can mount to multiple instances if all are read-only
- Pay for GB/mo provisioned depending on perf.class;plus snapshot GB/mo used
Cloud Filestore – (Zonal) Fully managed file-based storage
- “Predictably fast🏃♂️ performance for your file-based workloads”
- Accessible to GCE and GKE through your VPC, via NFSv3 protocol
- Primary use case is application migration to Cloud☁️ (“lift and shift”)🚜
- Fully manages file serving, but not backups
- Pay for provisioned TBs in “Standard” (slow) or “Premium” (fast🏃♂️) mode
- Minimum provisioned capacity of 1TB (Standard) or 2.5TB (Premium)
Cloud Storage (GCS) – (Regional, Multi-Regional) Infinitely Scalable⚖️, fully managed, versioned, and highly durable object storage
- Designed for 99.999999999% (11 9’s) durability
- Strong consistent💪 (even for overwrite PUTs and DELETEs)
- Integrated site hosting and CDN functionality
- Lifecycle♻️ transitions across classes: Multi-Regional, Regional, Nearline, Coldline🥶
- Diffs in cost & availability (99.5%, 99.9%, 99%, 99%), not latency (no thaw delay)
- All Classes have same API, so can use gsutil and gcsfuse
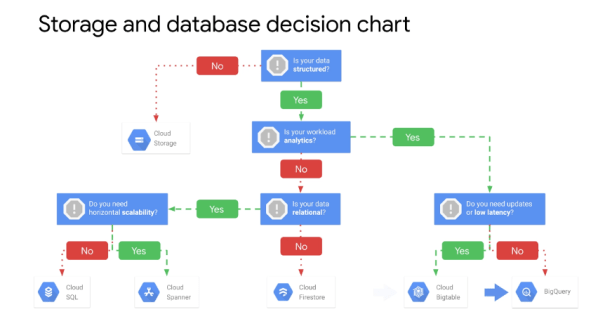
Databases
Cloud SQL – (Regional, Fully managed and reliable MySQL and PostgreSQL databases
- Supports automatic replication, backup, failover, etc.
- Scaling is manual (both vertically and horizontally)
- Effectively pay for underlying GCE instances and PDs
- Plus, some baked-in service fees
Cloud Spanner – (Regional, Multi-Regional), Global🌎 horizontally Scalable⚖️, strongly consistent 💪, relational database service”
- “From 1 to 100s or 1000s of nodes”
- “A minimum of 3 nodes is recommended for production environments.”
- Chooses Consistency and Partition – Tolerance (CP and CAP theorem)
- But still high Availability: SLA has 99.999% SLO (five nines) for multi-region
- Nothing is actually 100%, really
- Not based on fail-over
- Pay for provisioned node time (by region/multi-region) plus used storage-time

BigQuery (BQ)– Multi-Regional Serverless column-store data warehouse for analytics using SQL
- Scales⚖️ internally (TB in seconds and PB in minutes)
- Pay for GBs actually considered (scanned) during queries
- Attempts to reuse cached results, which are free
- Pay for data stored (GB-months)
- Relatively inexpensive
- Even cheaper when table not modified for 90 days (reading still fine)
- Pay for GBs added via streaming inserts
Cloud Datastore – (Regional, Multi-Regional) Managed & autoscale⚖️ NoSQL DB with indexes, queries, and ACID trans, support
- No joins or aggregates and must line up with indexes
- NOT, OR, and NOT EQUALS (<>,!=) operations not natively supported
- Automatic “built-in” indexes for simple filtering and sorting (ASC, DESC)
- Manual “composite” indexes for more complicated, but beware them “exploding”
- Pay for GB-months of storage🗄 used (including indexes)
- Pay for IO operations (deletes, reads, writes) performed (i.e. no pre-provisioning)
Cloud Bigtable – (Zonal) Low latency & high throughput NoSQL DB for large operational & analytical apps
- Supports open-source HBase API
- Integrates with Hadoop, Dataflow, Dataproc
- Scales⚖️ seamlessly and unlimitedly
- Storage🗄 autoscales⚖️
- Processing nodes must be scaled manually
- Pay for processing node hours
- GB-hours used for storage 🗄 (cheap HDD or fast🏃♂️ SSD)
Firebase Realtime DB & Cloud Firestore 🔥 – (Regional, Multi-Regional) NoSQL document📃 stores with ~real-time client updates via managed WebSockets
- Firebase DB is single (potentially huge) JSON doc, located only in central US
- Cloud☁️ Firestore has collection, documents📃, and contained data
- Free tier (Spark⚡️), flat tier (Flame🔥), or usage-based pricing (Blaze)
- Realtime Db: Pay more GB/month stored and GB downloaded
- Firestore: Pay for operations and much less for storage🗄 and transfer
Data Transfer ↔️
Data Transfer Appliance – Rackable, high-capacity storage 🗄 server to physically ship data to GCS
- Ingest only; not a way to avoid egress charges
- 100 TB or 480 TB/week is faster than a saturated 6 Gbps link🔗
Storage Transfer Service – (Global) Copies objects for you, so you don’t need to set up a machine to do it
- Destination is always GCS bucket 🗑
- Source can S3, HTTP/HTTPS endpoint, or another GCS bucket 🗑
- One-time or scheduled recurring transfers
- Free to use, but you pay for its actions
External Networking
Google Domains – (Global) Google’s registrar for domain names
- Private Whois records
- Built-in DNS or custom nameservers
- Support DNSSEC
- email📧 forwarding with automatic setup of SPF and DKIM (for built-in DNS)
Cloud DNS– (Global) Scalable⚖️, reliable, & managed authoritative Domain (DNS) service
- 100 % uptime guarantee
- Public and private managed zones
- Low latency Globally
- Supports DNSSEC
- Manage via UI, CLI, or API
- Pay fixed fee per managed zone to store and distribute DNS records
- Pay for DNS lookups (i.e. usage)
Static IP Addresses – (Regional, Global🌎 Reserve static IP addresses in projects and assign them to resources
- Regional IPs used for GCE instances & Network Load Balancers🏋️♀️
- Global IPs used for Global load balancers🏋️♀️:
- HTTP(S) SSL proxy, and TCP proxy
- Pay for reserved IPs that are not in use, to discourage wasting them
Cloud Load Balancing (CLB) – (Regional, Global🌎 High-perf, Scalable ⚖️ traffic🚦 distribution integrated with autoscaling & Cloud☁️ CDN
- SDN naturally handles spikes without any prewarming, no instances or devices
- Regional Network Load Balancer 🏋️♀️: health checks, round robin, session affinity
- Forwarding rules based on IP, protocol (e.g. TCP, UDP), and (optionally) port
- Global load balancers 🏋️♀️ w/ multi-region failover for HTTP(S), SSL proxy, & TCP proxy
- Prioritize low-latency connection to region near user, then gently fail over in bits
- Reacts quickly (unlike DNS) to changes in users, traffic🚦, network, health, etc.
- Pay by making ingress traffic🚦 billable (Cheaper than egress) plus hourly per rule
Cloud CDN – (Global) Low-latency content delivery based on HTTP(S) CLB integrated w/ GCE & GCS
- Supports HTTP/2 and HTTPS, but no custom origins (GCP☁️ only)
- Simple checkbox ✅ on HTTP(S) Load Balancer 🏋️♀️ config turns this on
- On cache miss, pay origin-> POP “cache fill” egress charges (cheaper for in-region)
- Always pay POP->clint egress charges, depending on location
- Pay for HTTP(S) request volume
- Pay per cache invalidation request (not per Resource⚙️ invalidated)
- Origin costs (e.g. CLB, GCS) can be much lower because cache hits reduce load
Virtual Private Cloud (VPC) – (Regional, Global), Global IP v4 unicast Software-Defined Network (SDN) for GCP☁️ resources
- Automatic mode is easy; custom mode gives control
- Configure subnets (each with a private IP range), routes, firewalls🔥, VPNs, BGP, etc.
- VPC is Global🌎 and subnets are regional (not zonal)
- Can be shared across multiple projects in same org and peered with other VPCs
- Can enable private (internal IP) access to some GCP☁️ services (e.g. BQ, GCS)
- Free to configure VPC (container)
- Pay to use certain services (e.g. VPN) and for network egress
Cloud Interconnect – (Regional, Multi-Regional) Options for connecting external networks to Google’s network
- Private connections to VPC via Cloud VPN or Dedicated/Partner Interconnect
- Public Google services (incl. GCP) accessible via External Peering (no SLAs)
- Direct Peering for high volume
- Carrier Peering via a partner for lower volume
- Significantly lower egress fees
- Except Cloud VPN, which remains unchanged
Internal Networking
Cloud Virtual Private Network (VPN)– (Regional) IPSEC VPN to connect to VPC via public internet for low-volume data connections
- For persistent, static connections between gateways (i.e. not for a dynamic client)
- Peer VPN gateway must have static (unchanging) IP
- Encrypted 🔐 link🔗 to VPC (as opposed to Dedicated interconnect), into one subnet
- Supports both static and dynamic routing
- 99.9% availability SLA
- Pay per tunnel-hour
- Normal traffic🚦 charges apply
Dedicated Interconnect – (Regional, Multi-Regional) Direct physical link 🔗 between VPC and on-prem for high-volume data connections
- VLAN attachment is private connection to VPC in one region: no public GCP☁️ APIs
- Region chosen from those supported by particular Interconnect Location
- Links are private but not Encrypted 🔐; can layer your own encryption 🔐
- Redundancy achieves 99.99% availability: otherwise, 99.9% SLA
- Pay fee 10 Gbps link, plus (relatively small) fee per VLAN attachment
- Pay reduced egress rates from VPC through Dedicated Interconnect
Cloud Router 👮♀️ – (Regional) Dynamic routing (BGP) for hybrid networks linking GCP VPCs to external networks
- Works with Cloud VPN and Dedicated Interconnect
- Automatically learns subnets in VPC and announces them to on-prem network
- Without Cloud Router👮♀️ you must manage static routes for VPN
- Changing the IP addresses on either side of VPN requires recreating it
- Free to set up
- Pay for usual VPC egress
CDN Interconnect – (Regional, Multi-Regional) Direct, low-latency connectivity to certain CDN providers, with cheaper egress
- For external CDNs, not Google’s Cloud CDN service
- Supports Akamai, Cloudflare, Fastly, and more
- Works for both pull and push cache fills
- Because it’s for all traffic🚦 with that CDN
- Contact CDN provider to set up for GCP☁️ project and which regions
- Free to enable, then pay less for the egress you configured
Machine Learning/AI 🧠
Cloud Machine Learning (ML) Engine – (Regional) Massively Scalable ⚖️ managed service for training ML models & making predictions
- Enables apps/devs to use TensorFlow on datasets of any size, endless use cases
- Integrates: GCS/BQ (storage), Cloud Datalab (dev), Cloud Dataflow (preprocessing)
- Supports online & batch predictions, anywhere: desktop, mobile, own servers
- HyperTune🎶 automatically tunes 🎶model hyperparameters to avoid manual tweaking
- Training: Pay per hour depending on chosen cluster capabilities (ML training units)
- Prediction: Pay per provisioned node-hour plus by prediction request volume made
Cloud Vison API👓 – (Global) Classifies images🖼 into categories, detects objects/faces, & finds/reads printed text
- Pre-trained ML model to analyze images🖼 and discover their contents
- Classifies into thousands of categories (e.g., “sailboat”, “lion”, “Eiffel Tower”)
- Upload images🖼 or point to ones stored in GCS
- Pay per image, based on detection features requested
- Higher price for OCR of Full documents📃 and finding similar images🖼 on the web🕸
- Some features are prices together: Labels🏷 + SafeSearch, ImgProps + Cropping
- Other features priced individually: Text, Faces, Landmarks, Logos
Cloud Speech API🗣 – (Global) Automatic Speech Recognition (ASR) to turn spoken word audio files into text
- Pre-trained ML model for recognizing speech in 110+ languages/variants
- Accepts pre-recorded or real-time audio, & can stream results back in real-time
- Enables voice command-and-control and transcribing user microphone dictations
- Handles noisy source audio
- Optionally filters inappropriate content in some languages
- Accepts contextual hints: words and names that will likely be spoken
- Pay per 15 seconds of audio processed
Cloud Natural Language API 💬 – (Global) Analyzes text for sentiment, intent, & content classification, and extracts info
- Pre-trained ML model for understanding what text means, so you can act on it
- Excellent with Speech API (audio), Vision API (OCR), & Translation API (or built-ins)
- Syntax analysis extracts tokens/sentences, parts of speech & dependency trees
- Entity analysis finds people, places, things, etc., labels🏷 them & links🔗 to Wikipedia
- Analysis for sentiment (overall) and entity sentiment detect +/- feelings & strength
- Content classification puts each document📃 into one of 700+ predefined categories
- Charged per request of 1000 characters, depending on analysis types requested
Cloud Translation API –(Global) Translate text among 100+ languages; optionally auto-detects source language
- Pre-trained ML model for recognizing and translating semantics, not just syntax
- Can let people support multi-regional clients in non-native languages,2-way
- Combine with Speech, Vision, & Natural Language APIs for powerful workflows
- Send plain text or HTML and receive translation in kind
- Pay per character processed for translation
- Also pay per character for language auto-detection
Dialogflow – (Global) Build conversational interfaces for websites, mobile apps, messaging, IoT devices
- Pre-trained ML model and service for accepting, parsing, lexing input & responding
- Enables useful chatbot and other natural user interactions with your custom code
- Train it to identify custom entity types by providing a small dataset of examples
- Or choose from 30+ pre-built agents (e.g. car🚙, currency฿, dates as starting template
- Supports many different languages and platforms/devices
- Free plan had unlimited text interactions and capped voice interactions
- Paid plan is unlimited but charges per request: more for voice, less for text
Cloud Video Intelligence API 📹 – (Regional, Global) Annotates videos in GCS (or directly uploaded) with info about what they contain
- Pre-trained ML model for video scene analysis and subject identification
- Enables you to search a video catalog the same way you search text documents📃
- “Specify a region where processing will take place (for regulatory compliance)”
- Label Detection: Detect entities within the video, such as “dog” 🐕, “flower” 🌷 or “car”🚙
- Shot Change Detection: Detect scene changes within the video🎞
- SafeSearch Detection: Detect adult content within the video🎞
- Pay per minute of video🎞 processed, depending on requested detection modes
Cloud Job Discovery– (Global) Helps career sites, company job boards, etc. to improve engagement & conversion
- Pre-trained ML model to help job seekers search job posting databases
- Most job sites rely on keyword search to retrieve content which often omits relevant jobs and overwhelms the job seeker with irrelevant jobs. For example, a keyword search with any spelling error returns) results, and a keyword search for “dental assistant” returns any “assistant” role that offers dental benefits.’
- Integrates with many job/hiring systems
- Lots of features, such as commute distance and recognizing abbreviations/jargon
- “Show me jobs with a 30-minute commute on public transportation from my home”
Big Data and IoT
Four Different Stages:
- Ingest – Pull in all the raw data in
- Store – Store data without data loss and easy retrieval
- Process – transform that raw data into some actionable information
- Explore & Visualize – turn the results of that analysis into something that’s valuable for your business
Cloud Internet of Things (IoT) Core– (Global) Fully managed service to connect, manage, and ingest data from device Globally
- Device Manager handles device identity, authentication, config & control
- Protocol Bridge publishes incoming telemetry to Cloud☁️ Pub/Sub for processing
- Connect securely using IoT industry standard MQTT or HTTPS protocols
- CA signed certificates can be used to verify device ownership on first connect
- Two-way device communication enables configuration & firmware updates
- Device shadows enable querying & making control changes while devices offline
- Pay per MB of data exchanged with devices; no per-device charge
Cloud Pub/Sub– (Global) Infinitely Scalable⚖️ at-least-once messaging for ingestion, decoupling, etc.
- “Global🌎 by default: Publish… and consume from anywhere, with consistent latency”.
- Messages can be up to 10 MB and undelivered ones stored for 7 days-but no DLQ
- Push mode delivers to HTTPS endpoints & succeeds on HTTP success status code
- “Slow-start” algorithm ramps up on success and backs off & retries, on failures
- Pull mode delivers messages to requestion clients and waits for ACK to delete
- Let’s clients set rate of consumption, and supports batching and long-polling
- Pay for data volume
- Min 1KB per publish/Push/Pull request (not by message)
Cloud Dataprep– (Global) Visually explore, clean, and prepare data for analysis without running 🏃♂️ servers
- “Data Wrangling” (i.e. “ad-hoc ETL”) for business analysts, not IT pros
- Who might otherwise spend 80% of their time cleaning data?
- Managed version of Trifacta Wrangler – and managed by Trifacta, not Google
- Source data from GCS, BQ, or file upload – formatted in CSV, JSON, or relational
- Automatically detects schemas, datatypes, possible joins, and various anomalies
- Pay for underlying Daaflow job, plus management overhead charge
- Pay for other accessed services (e.g. GCS, BQ)
Cloud Dataproc– (Zonal) Batch MapReduce processing via configurable, managed Spark & Hadoop clusters
- Handles being told to scale (adding or removing nodes) even while running 🏃♂️ jobs
- Integrated with Cloud☁️ Storage, BigQuery, Bigtable, and some Stackdriver services
- “Image versioning” switches between versions of Spark, Hadoop, & other tools
- Pay directly for underlying GCE servers used in the cluster – optionally preemptible
- Pay a Cloud Dataproc management fee per vCPU-hour in the cluster
- Best for moving existing Spark/Hadoop setups to GCP☁️
- Prefer Cloud Dataflow for new data processing pipelines – “Go with the flow”
Cloud Datalab 🧪– (Regional) Interactive tool 🔧 for data exploration🔎, analysis, visualization📊 and machine learning
- Uses Jupyter Notebook📒
- “[A]n open-source web🕸 application that allows you to create and share documents📃 that contain live code, equations, visualizations and narrative text. Use include data cleaning and transformation, numerical simulation, statistical modeling, data visualization, machine learning, and much more.”
- Supports iterative development of data analysis algorithms in Python🐍/ SQL/~JS
- Pay for GCE/GAE instance hosting and storing (on PD) your notebook📒
- Pay for any other resources accessed (e.g. BigQuery)
Cloud Data Studio– (Global) Big Data Visualization📊 tool 🔧 for dashboards and reporting
- Meaningful data stories/presentations enable better business decision making
- Data sources include BigQuery, Cloud SQL, other MySQL, Google Sheets, Google Analytics, Analytics 360, AdWords, DoubleClick, & YouTube channels
- Visualizations include time series, bar charts, pie charts, tables, heat maps, geo maps, scorecards, scatter charts, bullet charts, & area charts
- Templates for quick start; customization options for impactful finish
- Familiar G Suite sharing and real-time collaboration
Cloud Genomics 🧬– (Global) Store and process genomes🧬 and related experiments
- Query complete genomic🧬 information of large research projects in seconds
- Process many genomes🧬 and experiments in parallel
- Open Industry standards (e.g. From Global🌎 Alliance for Genomics🧬 and Health)
- Supports “Requester Pays” sharing
Identity and Access – Core Security🔒
Roles– (Global) collections of Permissions to use or manage GCP☁️ resources
- Permissions allow you to perform certain actions: Service.Resource.Verb
- Primitive Roles: Owner, Editor, Viewer
- Viewer is read-only; Editor can change things; Owner can control access & billing
- Pre-date IAM service, may still be useful (e.g., dev/test envs), but often too broad
- Predefined Roles: Give granular access to specific GCP☁️ resources (IAM)
- E.g.: roles/bigquery.dataEditor, roles/pub/sub.subscriber
- Custom Roles: Project- or Org-level collections you define of granular permissions
Cloud Identity and Access Management (IAM)– (Global) Control access to GCP☁️ resources: authorization, not really authentication/identity
- Member is user, group, domain, service account, or the public (e.g. “allUsers”)
- Individual Google account, Google group, G Suite/ Cloud Identity domain
- Service account belongs to application/instance, not individual end user
- Every identity has a unique e-mail address, including service accounts
- Policies bind Members to Roles at a hierarchy👑 level: Org, Folder📂, Project, Resource⚙️
- Answer: Who can do what to which thing(s)?
- IAM is free; pay for authorized GCP☁️ service usage

Service Accounts– (Global) Special types of Google account that represents an application, not an end user
- Can be “assumed” by applications or individual users (when so authorized)
- “Important: For almost all cases, whether you are developing locally or in a production application, you should use service accounts, rather than user accounts or API keys🔑.”
- Consider resources and permissions required by application; use least privilege
- Can generate and download private keys🔑 (user-managed keys🔑), for non-GCP☁️
- Cloud-Platform-managed keys🔑 are better, for GCP☁️ (i.e. GCF, GAE, GCE, and GKE)
- No direct downloading: Google manages private keys🔑 & rotates them once a day
Cloud Identity– (Global) Identity as a Service (IDaaS, not DaaS) to provision and manage users and groups
- Free Google Accounts for non-G-Suite users, tied to a verified domain
- Centrally manage all users in Google Admin console; supports compliance
- 2-Step verification (2SV/MFA) and enforcement, including security🔒 keys🔑
- Sync from Active Directory and LDAP directories via Google Cloud☁️ Directory Sync
- Identities work with other Google services (e.g. Chrome)
- Identities can be used to SSO with other apps via OIDC, SAML, OAuth2
- Cloud Identity is free; pay for authorized GCP☁️ service usage
Security Key Enforcement– (Global) USB or Bluetooth 2-step verification device that prevents phishing🎣
- Not like just getting a code via email📧 or text message…
- Eliminates man-in-the-middle (MITM) attacks against GCP☁️ credentials
Cloud Resource Manager– (Global) Centrally manage & secure organization’s projects with custom Folder📂 hierarchy👑
- Organization Resource⚙️ is root node in hierarchy👑, folders📂 per your business needs
- Tied 1:1 to a Cloud Identity / G Suite domain, then owns all newly created projects
- Without this organization, specific identities (people) must own GCP☁️ projects
- “Recycle bin” allows undeleting projects
- Define custom IAM policies at organization, Folder📂, or project levels
- No charge for this service

Cloud Identity-Aware Proxy (IAP)– (Global) Guards apps running 🏃♂️ on GCP☁️ via identity verification, not VPN access
- Based on CLB & IAM, and only passes authed requests through
- Grant access to any IAM identities, incl. group & service accounts
- Relatively straightforward to set up
- Pay for load balancing🏋️♀️ / protocol forwarding rules and traffic🚦
Cloud Audit Logging– (Global) “Who did what, where and when?” within GCP☁️ projects
- Maintains non-tamperable audit logs for each project and organization:
- Admin Activity and System Events (400-day retention)
- Access Transparency (400-day retention)
- Shows actions by Google support staff
- Data Access (30-day retention)
- For GCP-visible services (e.g. Can’t see into MySQL DB on GCE)
- Data Access logs priced through Stackdriver Logging; rest are free
Security Management – Monitoring🎛 and Response
Cloud Armor🛡 – (Global) Edge-level protection from DDoS & other attacks on Global🌎 HTTP(S) LB🏋️♀️
- Offload work: Blocked attacks never reach your systems
- Monitor: Detailed request-level logs available in Stackdriver Logging
- Manage Ips with CIDR-based allow/block lists (aka whitelist/blacklist)
- More intelligent rules forthcoming (e.g. XSS, SQLi, geo-based🌎, custom)
- Preview effect of changes before making them live
- Pay per policy and rule configured, plus for incoming request volume
Cloud Security Scanner– (Global) Free but limited GAE app vulnerability scanner with “very low false positive rates”
- “After you set up a scan, Cloud☁️ Security🔒 Scanner automatically crawls your application, following all links🔗 within the scope of your starting URLs, and attempts to exercise as many user inputs and event handlers as possible.”
- Can identify:
- Cross-site-scripting (XSS)
- Flash🔦 injection💉
- Mixed content (HTTP in HTTPS)
- Outdated/insecure libraries📚
Cloud Data Loss Prevention API (DLP) – (Global) Finds and optionally redacts sensitive info is unstructured data streams
- Helps you minimize what you collect, expose, or copy to other systems
- 50+ sensitive data detectors, including credit card numbers, names, social security🔒 numbers, passport numbers, driver’s license numbers (US and some other jurisdictions), phone numbers, and other personally identifiable information (PII)
- Data can be sent directly, or API can be pointed at GCS, BQ, or Cloud☁️ DataStore
- Can scan both text and images🖼
- Pay for amount of data processed (per GB) –and gets cheaper when large volume
- Pricing for storage 🗄now very simple (June 2019), but for streaming is still a mess
Event Threat Detection (ETD)– (Global) Automatically scans your Stackdriver logs for suspicious activity
- Uses industry-leading threat intelligence, including Google Safe Browsing
- Quickly detects many possible threats, including:
- Malware, crypto-mining, outgoing DDoS attacks, port scanning, brute-force SSH
- Also: Unauthorized access to GCP☁️ resources via abusive IAM access
- Can export parsed logs to BigQuery for forensic analysis
- Integrates with SIEMs like Google’s Cloud☁️ SCC or via Cloud Pub/Sub
- No charge for ETD, but charged for its usage of other GCP☁️ services (like SD Logging)
Cloud Security Command Center (SCC) – (Global)
- “Comprehensive security🔒 management and data risk platform for GCP☁️”
- Security🔒 Information and Event Management (SIEM) software
- “Helps you prevent, detect & respond to threats from a single pane of glass”
- Use: Security🔒 Marks” (aka “marks”) to group, track, and manage resources
- Integrate ETD, Cloud☁️ Scanner, DLP, & many external security🔒 finding sources
- Can alert 🔔 to humans & systems; can export data to external SIEM
- Free! But charged for services used (e.g. DLP API, if configured)
- Could also be charged for excessive uploads of external findings
Encryption Key Management 🔐
Cloud Key Management Services (KMS)– (Regional, Multi-Regional, Global) Low-latency service to manage and use cryptographic keys🔑
- Supports symmetric (e.g. AES) and asymmetric (e.g. RSA, EC) algorithms
- Move secrets out of code (and the like) and into the environment, in a secure way
- Integrated with IAM & Cloud☁️ Audit Logging to authorize & track key🔑 usage
- Rotate keys🔑 used for new encryption 🔐 either automatically or on demand
- Still keeps old active key🔑 versions, to allow decrypting
- Key🔑 deletion has 24-hour delay, “to prevent accidental or malicious data loss”
- Pay for active key🔑 versions stored over time
- Pay for key🔑 use operations (i.e. encrypt/decrypt; admin operation are free)
Cloud Hardware Security Module (HSM)– (Regional, Multi-Regional, Global) Cloud KMS keys🔑 managed by FIPS 140-2 Level 3 certified HSMs
- Device hosts encryption 🔐 keys🔑 and performs cryptographic operations
- Enables you to meet compliance that mandates hardware environment
- Fully integrated with Cloud☁️ KMS
- Same API, features, IAM integration
- Priced like Cloud KMS: Active key🔑 versions stored & key🔑 operations
- But some key🔑 types more expensive: RSA, EC, Long AES
Operations and Management
Google Stackdriver– (Global) Family of services for monitoring, logging & diagnosing apps on GCP/AWS/hybrid
- Service integrations add lots of value – among Stackdriver and with GCP☁️
- One Stackdriver account can track multiple:
- GCP☁️ projects
- AWS☁️ accounts
- Other resources
- Simple usage-based pricing
- No longer previous system of tiers, allotments, and overages
Stackdriver Monitoring– (Global) Gives visibility into perf, uptime, & overall health of Cloud☁️ apps (based on collectd)
- Includes built-in/custom metrics, dashboards, Global🌎 uptime monitoring, & alerts
- Follow the trail: Links🔗 from alerts to dashboards/charts to logs to traces
- Cross-Cloud☁️: GCP☁️, of course, but monitoring🎛 agent also supports AWS
- Alerting policy config includes multi-condition rules & Resource⚙️ organization
- Alert 🔔 via email, GCP☁️ Mobile App, SMS, Slack, PagerDuty, AWS SNS, webnook, etc.
- Automatic GCP☁️/Anthos metrics always free
- Pay for API calls & per MB for custom or AWS metrics
Stackdriver Logging – (Global) Store, search🔎, analyze, monitor, and alert 🔔 on log data & events (based on Fluentd)
- Collection built into some GCP☁️, AWS support with agent, or custom send via API
- Debug issues via integration with Stackdriver Monitoring, Trace & Error Reporting
- Crate real-time metrics from log data, then alert 🔔 or chart them on dashboards
- Send real-time log data to BigQuery for advanced analytics and SQL-like querying
- Powerful interface to browse, search, and slice log data
- Export log data to GCS to cost-effectively store log archives
- Pay per GB ingested & stored for one month, but first 50GB/project free
Stackdriver Error Reporting– (Global) Counts, analyzes, aggregates, & tracks crashes in helpful centralized interface
- Smartly aggregates errors into meaningful groups tailored to language/framework
- Instantly alerts when a new app error cannot be grouped with existing ones
- Link🔗 directly from notifications to error details:
- Time chart, occurrences, affected user count, first/last seen dates, cleaned stack
- Exception stack trace parser know Java☕️, Python🐍, JavaScript, Ruby💎,C#,PHP, & Go🟢
- Jump from stack frames to source to start debugging
- No direct charge; pay for source data in Stackdriver Logging
Stackdriver Trace– (Global) Tracks and displays call tree 🌳 & timings across distributed systems, to debug perf
- Automatically captures traces from Google App Engine
- Trace API and SDKs for Java, Node.js, Ruby, and God Capture traces from anywhere
- Zipkin collector allows Zipkin tracers to submit data to Stackdriver Trace
- View aggregate app latency info or dig into individual traces to debug problems
- Generate reports on demand and get daily auto reports per traced app
- Detects app latency shift (degradation) over time by evaluating perf reports
- Pay for ingesting and retrieving trace spans
Stackdriver Debugger– (Global) Grabs program state (callstack, variables, expressions) in live deploys, low impact
- Logpoints repeat for up to 24h; fuller snapshots run once but can be conditional
- Source view supports Cloud Source Repository, Github, Bitbucket, local, & upload
- Java☕️ and Python🐍 supported on GCE, GKE, and GAE (Standard and Flex)
- Node.js and Ruby💎supported on GCE, GKE, and GAE Flex; Go only on GCE & GKE
- Automatically enabled for Google App Engine apps, agents available for others
- Share debugging sessions with others (just send URL)
Stackdriver Profiler– (Global) Continuous CPU and memory profiling to improve perf & reduce cost
- Low overhead (typical: 0.5%; Max: 5%) – so use it in prod, too!
- Supports Go, Java, Node,js, and Python (3.2+)
- Agent-based
- Saves profiles for 30 days
- Can download profiles for longer-term storage
Cloud Deployment Manager– (Global) Create/manage resources via declarative templates: “Infrastructure as Code”
- Declarative allows automatic parallelization
- Templated written in YAML, Python🐍, or Jinja2
- Supports input and output parameters, with JSON schema
- Create and update of deployments both support preview
- Free service: Just pay for resources involved in deployments
Cloud Billing API 🧾– (Global) Programmatically manage billing for GCP☁️ projects and get GCP☁️ pricing
- Billing 🧾 Config
- List billing🧾 accounts; get details and associated projects for each
- Enable (associate), disable (disassociated), or change project’s billing account
- Pricing
- List billable SKUs; get public pricing (including tiers) for each
- Get SKU metadata like regional availability
- Export of current bill to GCS or BQ is possible – but configured via console, not API
Development and APIs
Cloud Source Repositories – (Global) Hosted private Git repositories, with integrations to GCP☁️ and other hosted repos
- Support standard Git functionality
- No enhanced workflow support like pull requests
- Can set up automatic sync from GitHub or Bitbucket
- Natural integration with Stackdriver debugger for live-debugging deployed apps
- Pay per project-user active each month (not prorated)
- Pay per GB-month of data storage 🗄(prorated), Pay per GB of Data egress
Cloud Build 🏗 – (Global) Continuously takes source code and builds, tests and deploys it – CI/CD service
- Trigger from Cloud Source Repository (by branch, tag or commit) or zip🤐 in GCS
- Can trigger from GitHub and Bitbucket via Cloud☁️ Source Repositories RepoSync
- Runs many builds in parallel (currently 10 at a time)
- Dockerfile: super-simple build+push – plus scans for package vulnerabilities
- JSON/YAML file: Flexible🧘♀️ & Parallel Steps
- Push to GCR & export artifacts to GCS – or anywhere your build steps wrtie
- Maintains build logs and build history
- Pay per minute of build time – but free tier is 120 minutes per day

Container Registry (GCR) 📦– (Regional, Multi-Regional) Fast🏃♂️, private Docker🐳 image storage 🗄 (based on GCS) with Docker🐳 V2 Registry API
- Creates & manages a multi-regional GCS bucket 🗑, then translates GCR calls to GCS
- IAM integration simplifies builds and deployments within GCP☁️
- Quick deploys because of GCP☁️ networking to GCS
- Directly compatible with standard Docker🐳 CLI; native Docker🐳 Login Support
- UX integrated with Cloud☁️ Build & Stackdriver Logs
- UI to manage tags and search for images🖼
- Pay directly for storage 🗄and egress of underlying GCS (no overhead)
Cloud Endpoints – (Global) Handles authorization, monitoring, logging, & API keys🔑 for APIs backed by GCP☁️
- Proxy instances are distributed and hook into Cloud Load Balancer 🏋️♀️
- Super-fast🏃♂️ Extensible Service Proxy (ESP) container based on nginx: <1 ms /call
- Uses JWTs and integrates with Firebase 🔥, AuthO, & Google Auth
- Integrates with Stackdriver Logging and Stackdriver Trace
- Extensible Service Proxy (ESP) can transcode HTTP/JSON to gRPC
- But API needs to be Resource⚙️-oriented (i.e RESTful)
- Pay per call to your API
Apigee API Platform – (Global) Full-featured & enterprise-scale API management platform for whole API lifecycle
- Transform calls between different protocols: SOAP, REST, XML, binary, custom
- Authenticate via OAuth/SAML/LDAP: authorize via Role-Based Access Control
- Throttle traffic🚦 with quotas, manage API versions, etc.
- Apigee Sense identifies and alerts administrators to suspicious API behaviors
- Apigee API Monetization supports various revenue models /rate pans
- Team and Business tiers are flat monthly rate with API call quotas & feature sets
- “Enterprise” tier and special feature pricing are “Contact Sales”
Test Lab for Android – (Global) Cloud☁️ infrastructure for running 🏃♂️ test matrix across variety of real Android devices
- Production-grade devices flashed with Android version and locale you specify
- Robo🤖 test captures log files, saves annotated screenshots & video to show steps
- Default completely automatic but still deterministic, so can show regressions
- Can record custom script
- Can also run Espresso and UI Automator 2.0 instrumentation tests
- Firebase Spark and Flame plans have daily allotment of physical and virtual tests
- Blaze (PAYG) plan charges per device-hour-much less for virtual devices
“Well, we all shine☀️ on… Like the moon🌙 and the stars🌟 and the sun🌞”
Thanks –
–MCS





































{kind=link}