So, this week we decided to go down that road 🚙 and I am happy 😊 to report we passed.
“That’s what the flair is about… it’s about fun 😃!” — Stan from Chotchkie’s
Ok, so besides picking up some additional flair to match our AWS Practitioner badge it does provide us with some additional street “Cloud ☁️ Cred” and we can also show lack of favoritism of one cloud ☁️ provider over another. The bottom line is all clouds☁️ are good 😊 and very powerful⚡️!
To help prepare for the exam📝, we turned to several resources. Fortunately, there is a lot of great content out there. For a quick primer we turned to John Savill 💪 who literally got pumped up 🏋🏻♂️ and delivered an excellent primer on Azure architecture and the Core Concepts through his AZ-900 Azure Fundamentals Hints and Tips Youtube video and to “Tech Trainer” Tim Warner who was happy 😊 to be our instructor 👨🏫 through his amazing Microsoft Azure Fundamentals Study Guide YouTube Series
Finally, just to get a feel for types of questions that might appear on the exam 📝 I purchased TestPrepTraining – Microsoft Azure Fundamentals (AZ-900) Practice Exam which provided over 1,000 Azure Fundamental-type questions. With that being said there were some similar questions I saw in the course’s practice tests but there were still many questions on my actual exam 📝 that I had never seen 👀 before. In fact, the questions were even in a completely different format then the courseware. Overall, I was quite impressed with how Microsoft structured this test. They made it quite challenging and with the expectations that you had to have practical experience using the Azure Portal and that you just didn’t memorize a bunch concepts and plethora of questions.
“My, my, my, I’m once bitten 🦈 twice shy baby”
For those who might remember when I first attempted to take the AWS Cloud Practitioner Exam, it didn’t exactly go as planned. So perhaps now, I might be a little gun shy ☺️ or just proponent of having a highly available and fault tolerant environment (like the cloud ☁️ itself) to be used for taking these exams 📝. So, in preparation of the exam 📝, I prepared 2 Mac books 💻 and one Windows laptop to be available with the secure OnVUE browser hours ⏳ before the test to mitigate against any unforeseen circumstances.
“Hold your head up… Keep your head up, movin’ on”
Below are some areas I am considering for my travels next week:
SQL Server 2019
Google Cloud Certified Associate Cloud Engineer Path
Back at the end of July, we decided to re-route course and go back to the basics with AWS Cloud☁️ focusing on the core concepts and principals of the AWS. Despite hitting a temporary obstacle, we subsequently took and passed the AWS Certified Cloud Practitioner certification exam📝 last week. Feeling the need to spread the love❤️ around the Troposphere we decided we should circle 🔵 back to Microsoft’s very popular cloud☁️ offering Azure and focus on the “fundies” or Fundamentals of Azure. Of course, this wasn’t our first time 🕰 at this rodeo🤠🐴. We spent several occasions in the Microsoft Stratosphere☁️☁️ before. The most recent was looking at Microsoft’s NoSQL Azure offerings. This time 🕰 we would concentrate specifically on General Cloud☁️ Concepts, Azure Architectural Components, Microsoft Azure Core Services, Security🔒, Privacy🤫, Compliance, and Pricing💰, Service Level Agreements, and Lifecycles. To obtain such knowledge we would need to explore several resources starting with our first course 🍽 of Azure fundamentals which was an amazing compilation of rich documentation, vignettes🎞 from current and former blue badgers/ Cloud☁️ Advocates Anthony Bortolo, Sonia Cuff, Phoummala Schmitt, Susan Hinton, Rick Claus, Christina Warren, Pierre Roman and Scott Cate and several short labs🧪 that give you free access to the Azure Cloud☁️ and let you implement solutions. For our second course 🍽 we went out to YouTube and found 5 ½ hours ⏳ of goodness 😊 with Paul Browning’s awesome videos on “Microsoft Azure Fundamentals (AZ 900) – Complete Course” and then for encore we went to Pluralsight and visited with both Michael Brown and his Microsoft Azure Security🔒 and Privacy🤫 Concepts and with Steve Buchanan and his Microsoft Azure Pricing and Support Options because who can ever get enough of Security🔒 and Pricing💰?
“So, I look in the sky, but I look in vain…Heavy cloud☁️, but no rain🌧”
General Cloud☁️ Concepts
First, let’s review… What is cloud☁️ computing anyway? There are numerous meanings out there. According to Wikipedia“Cloud☁️ computing is the on-demand availability of computer system resources, especially data storage🗄 (cloud☁️ storage🗄) and computing power🔌, without direct active management by the user. “
It’s really just a catchy name. So, despite contrary to belief Cloud☁️ Computing has nothing to do with the clouds☁️ ☁️ or the weather☔️ in the sky. In simplest terms it means sharing of pooled computing resources over the Internet. And are you ready for the catcher? “that you can rent”. In other words, you pay for what you use. Opposed to traditional computing way where a company or organization would invest in potentially expensive real estate to house owned Compute🖥, Storage🗄, Networking or fancy Analytics.
So now we are faced with the argument Capital expenditure (traditional computing cost model) versus operational expenditure (Cloud☁️ Computing cost model)
Capital expenditure (CapEx) 💰consists of the funds that a company uses to purchase major physical goods or services that the company will use for more than one year and the value will depreciate over time 🕰
Operational expenditure (OpEx) 💰are deducted in the same year they’re made, allowing you to deduct those from your revenues faster.
So, looking from a cost perspective, the cloud☁️ can offer a better solution for a better cost since the cloud☁️ provider’s already has those, so you would benefit from the economies of scale⚖️.
That’s great but let’s leave the expenses to the bean counters. After all we are technologists and we want the best performance and efficient technology solutions. So, what other benefits does Cloud☁️ provide me? How about Scalability ⚖️, Elasticity 🧘♀️, Agility 💃, Fault Tolerance, High Availability, Disaster🌪 Recovery and Security🔒.
Scalability ⚖️: Cloud☁️ will increase or decrease resources and services used based on the demand or workload at any given time 🕰. Cloud☁️ supports both vertical ⬆️ and horizontal ↔️ scaling ⚖️ depending on your needs.
Elasticity 🧘♀️: Cloud☁️ compensate spike 📈 or drop 📉 in demand by automatically adding or removing resources.
Agility 💃: Cloud☁️ eliminates the burdens of maintaining software patches, hardware setup, upgrades, and other IT management tasks. All of this is automatically done for you. Allowing you to focus on what matters: building and deploying applications.
Fault Tolerance: Cloud☁️ has fully redundant datacenters located in various regions all over the globe.
High Availability & Disaster Recovery: Cloud☁️ can replicate your services into multiple regions for redundancy and locality or select a specific region to ensure you meet data-residency and compliance laws for your customers.
Security🔒: Cloud☁️ offers a broad set of policies, technologies, controls, and expert technical skills that can provide better security🔒 than most organizations can otherwise achieve.
Ok, now I am sold. But what types of clouds☁️ are there?
There are multiple types of cloud☁️ computing services, but the three main ones are:
Infrastructure as a service (IaaS) – enables applications to run🏃🏻on the cloud☁️ instead of using their own infrastructures. Allows the most control over provided hardware that runs 🏃 your applications
Platform as a Service (PaaS)- enables developers to create as software without investing in expensive 🤑 hardware. Allows you to create an application quickly without managing the underlying infrastructure.
Software as a Service (SaaS) – provides answers to desktop needs for end users. Based on an architecture where one version of the application is used for all customers and licensed through a monthly or annual subscription.
What about Cloud☁️ Deployment models? Well, there are multiple types of cloud☁️ deployment models out there as well.
Public cloud☁️: cloud☁️ vendor that provides cloud☁️ services to multiple clients. All of the clients securely 🔒 share the same hardware in the back end.
Private cloud☁️: organization uses their own hardware and software resources to achieve cloud☁️ services.
Hybrid cloud☁️: this cloud☁️ model is a combination of both private and public cloud☁️ models.
Community cloud☁️: this model consists of a pool of computer resources. These resources are available to the different organizations with common needs. Clients or tenants can access the resources quickly and securely🔒. Clients are referred to as tenants.
“Blue skies, smilin’ 😊 at me Nothin’ but blues skies do I see”
So now that we expounded the virtues of Cloud☁️ computing Concepts let’s take a deeper a look on what we came for…
Microsoft Azure is a cloud☁️ computing service created by Microsoft for building, testing, deploying, and managing applications and services through a global network of Microsoft managed data centers.
“Architecture starts when you carefully put two bricks🧱 together. There it begins.”
Azure Architectural Components
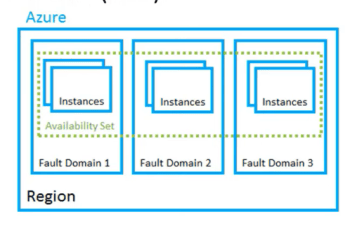
Microsoft Azure is made up of data centers located around the globe 🌎. These data centers are organized and made available to end users by region. A region is a geographical 🌎 area on the planet 🌎 containing at least one, but potentially multiple data centers that are in close proximity and networked together with a low-latency network.
Azure divides the world 🌎 into geographies 🌎 that are defined by geopolitical boundaries or country borders. An Azure geography is a discrete market typically containing two or more regions that preserves data residency and compliance boundaries.
Availability sets are a way for you to ensure your application remains online if a high-impact maintenance event is required, or if a hardware failure occurs. Availability sets are made up of Update domains (UD) and Fault domains (FD).
Fault domains is a logical group of underlying hardware that share a common power🔌 source and network switch, similar to a rack within an on-premise data center.
Update domains is a logical group of underlying hardware that can undergo maintenance or be rebooted at the same time 🕰. An update domain is a group of VMs that are set for planned maintenance events at the same time 🕰.
Paired regions support redundancy across two predefined geographic 🌎 regions, ensuring that even if an outage affects an entire Azure region, your solution is still available.
Additional advantages of regional pairs:
In the event of a wider Azure outage, one region is prioritized out of every pair to help reduce the time 🕰 to restore for applications.
Planned Azure updates are rolled out to paired regions one at a time 🕰 to minimize downtime 🕰 and risk of application outage.
Data continues to reside within the same geography as its pair (except for Brazil South) for tax and law enforcement jurisdiction purposes.
Availability Zones are physically separate locations within an Azure region that use availability sets to provide additional fault tolerance.
Resource group is a unit of management for your resources in Azure. A resource group is like container that allows you to aggregate and manage all the resources required for your application in a single manageable unit.
Azure Resource Manager is a management layer in which resource groups and all the resources within it are created, configured, managed, and deleted.
“It is our choices, Harry, that show what we truly are, far more than our abilities.”― J.K. Rowling
Azure Services
Azure provides over 100 services that enable you to do everything from running 🏃 your existing applications on virtual machines to exploring 🔦new software paradigms such as intelligent bots and mixed reality. Below are some of the services available in Azure:
Azure compute 🖥 – is an on-demand computing service for running cloud-based ☁️ applications.
There are four common techniques for performing compute 🖥 in Azure:
Virtual machines – software emulations of physical computers 🖥 .
Containers – virtualization environment for running 🏃 applications.
Azure App Service – (PaaS) offering in Azure that is designed to host enterprise-grade web-oriented applications
Serverless computing – cloud☁️ hosted execution environment that runs 🏃 your code but completely abstracts the underlying hosting environment.
Azure Virtual Machines (VMs) (IaaS) lets you create and use virtual machines in the cloud☁️.
Scaling VMs in Azure
Availability sets is a logical grouping of two or more VMs that help keep your application available during planned or unplanned maintenance 🧹.
Up to three fault domains that each have a server rack with dedicated power🔌 and network resources
Five logical update domains which then can be increased to a maximum of 20
Azure Virtual Machine Scale⚖️ Sets let you create and manage a group of identical, load balanced VMs.
Azure Batch enables large-scale⚖️ job scheduling and compute 🖥 management with the ability to scale⚖️ to tens, hundreds, or thousands of VMs.
Starts a pool of compute 🖥 VMs for you
Installs applications and staging data
Runs 🏃jobs with as many tasks as you have
Identifies failures
Re-queues work
Scales ⚖️ down the pool as work completes
Containers in Azure
Azure supports Docker🐳 containers (a standardized container model), and there are several ways to manage containers in Azure.
Azure Container Instances (ACI)
Azure Kubernetes Service (AKS)☸️
Azure Container Instances (ACI) offers the fastest and simplest way to run🏃🏻 a container in Azure.
Azure Kubernetes Service (AKS)☸️ is a complete orchestration service for containers with distributed architectures with multiple containers.
Containers are often used to create solutions using a microservice architecture. This architecture is where you break solutions into smaller, independent pieces.
Azure App Service
Azure App Service (PaaS) enables you to build and host web apps, background jobs, mobile📱backends, and RESTful 😴 APIs in the programming language of your choice without managing infrastructure. It offers automatic scaling ⚖️ and high availability.
App Service, you can host most common app service styles, including:
Web apps- includes full support for hosting web apps using ASP.NET, ASP.NET Core, Java☕️ , Ruby 💎, Node.js, PHP, or Python 🐍 .
API apps – build REST-based 😴 Web 🕸APIs using your choice of language and framework
Web Jobs – allows you to run🏃🏻 a program (.exe, Java☕️ , PHP, Python 🐍 , or Node.js) or script (.cmd, .bat, PowerShell⚡️🐚, or Bash🥊) in the same context as a web 🕸 app, API app, or mobile 📱 app. They can be scheduled or run🏃🏻 by a trigger 🔫.
Mobile📱app back-ends – quickly build a backend for iOS and Android apps.
Azure Networking
Azure Virtual Network enables many types of Azure resources such as Azure VMs to securely🔒 communicate with each other, the internet, and on-premises networks. Virtual networks can be segmented into one or more subnets. Subnets help you organize and secure🔒 your resources in discrete sections.
Azure Load Balancer is a load balancer service that Microsoft provides that helps take care of the maintenance for you. Load Balancer supports inbound and outbound scenarios, provides low latency and high throughput ↔️, and scales⚖️ up to millions of flows for all Transmission Control Protocol (TCP) and User Datagram Protocol (UDP) applications. Azure Application Gateway
VPN gateway is a specific type of virtual network gateway that is used to send encrypted traffic🚦 between an Azure Virtual Network and an on-premises location over the public internet. It provides a more secure 🔒 connection from on-premises to Azure over the internet.
Application Gateway is a load balancer designed for web applications. It uses Azure Load Balancer at the transport level (TCP) and applies sophisticated URL-based routing rules to support several advanced scenarios.
Here are some of the benefits of using Azure Application Gateway over a simple load balancer:
Cookie 🍪 affinity.
SSL termination
Web 🕸 application firewall🔥 (WAF)
URL rule-based routes.
Rewrite HTTP headers
Content delivery network (CDN) is a distributed network of servers that can efficiently deliver web 🕸 content to users. It is a way to get content to users in their local region to minimize latency.
Azure Storage🗄is a service that you can use to store files📁, messages✉️, tables , and other types of information.
Disk storage🗄 provides disks for virtual machines, applications, and other services to access and use as they need, similar to how they would in on-premises scenarios. Disk storage🗄 allows data to be persistently stored and accessed from an attached virtual hard disk.
Azure Blob storage🗄 is object storage🗄 solution for the cloud☁️. Blob storage🗄 is optimized for storing massive amounts of unstructured data, such as text or binary data.
Blob storage🗄 is ideal for:
Serving images or documents directly to a browser.
Storing files for distributed access.
Streaming video 📽 and audio 📻.
Storing data for backup and restore, disaster recovery, and archiving.
Storing data for analysis by an on-premises or Azure-hosted service.
Azure Files Storage🗄 enables you to set up highly available network file shares that can be accessed by using the standard Server Message Block (SMB) protocol. That means that multiple VMs can share the same files with both read and write access. You can also read the files using the REST 😴 interface or the storage🗄 client libraries 📚
File shares can be used for many common scenarios:
Many on-premises applications use file shares.
Configuration files 📂 can be stored on a file share and accessed from multiple VMs.
Diagnostic logs, metrics, and crash dumps are just three examples of data that can be written to a file 📂 share and processed or analyzed later.
Azure Archive Blob Storage🗄
Azure Archive Blob storage🗄 is designed to provide organizations with a low cost means of delivering durable, highly available, secure cloud☁️ storage🗄 for rarely accessed data with flexible latency requirements. Azure storage🗄 offers different access tiers include:
Hot 🥵 – Optimized for storing data that is accessed frequently.
Cool 🥶 – Optimized for storing data that is infrequently accessed and stored for at least 30 days.
Archive 🗃 – Optimized for storing data that is rarely accessed and stored for at least 180 days with flexible latency requirements (on the order of hours).
Storage🗄 Replication
Azure regions and geographies🌎 become important when you consider the available storage🗄 replication options. Depending on the storage🗄 type, you have different replication options.
Locally redundant storage🗄 (LRS)- Replicates your data 3x within the region in which you create your storage🗄 account.
Zone redundant storage🗄 (ZRS) – Replicates your data 3x across two to three facilities, either within a single region or across two regions.
Geo-redundant storage🗄 (GRS) – Replicates your data to secondary region that is hundreds of miles away from the primary region.
Read-access Geo-Redundant storage🗄 (RA-GRS)- Replicates your data to a secondary region, as with GRS, but also then provides read only access to the data in the secondary location.
Azure Database🛢 services are fully managed PaaS database🛢 services. Enterprise-grade performance with built-in high availability, scales⚖️ quickly and reach global 🌎 distribution.
Azure Cosmos DB🪐is a globally 🌎distributed database🛢 service that enables you to elastically and independently scale⚖️ throughput and storage🗄 across any number of Azure’s geographic 🌎 regions. It supports schema-less data that lets you build highly responsive and Always On applications to support constantly changing data.
Azure SQL Database🛢 is a relational database🛢 as a service (DBaaS) based on the latest stable version of Microsoft SQL Server database🛢 engine. SQL Database🛢 is a high-performance, reliable, fully managed and secure database🛢 without needing to manage infrastructure. SQL database🛢 offers 4 service tiers to support lightweight to heavyweight 🏋️♀️ database🛢 loads:
Basic
Standard
Premium
Premium RS
Azure Database🛢 for MySQL is a relational database🛢 service powered by the MySQL community edition. It’s a fully managed database🛢 as a service offering that can handle mission-critical workloads with predictable performance and dynamic Scalability ⚖️.
Azure Database🛢 for PostgreSQL is a relational database🛢 service based on the open-source Postgres database🛢 engine. It’s a fully managed database-as-a-service offering that can handle mission-critical workloads with predictable performance, security🔒, high availability, and dynamic Scalability ⚖️.
Azure Database🛢 Migration Service is a fully managed service designed to enable seamless migrations from multiple database🛢 sources to Azure data platforms with minimal downtime 🕰 (online migrations).
Dynamic Scalability ⚖️ enables your database🛢 to transparently respond to rapidly changing resource requirements and enables you to only pay for the resources that you need when you need them.
Elastic pools to maximize resource utilization
Elastic pools are designed dial performance up or down on demand especially if usage patterns are relatively predictable.
Azure Marketplace
Azure Marketplace is a service on Azure that helps connect end users with Microsoft partners, independent software vendors (ISVs), and start-ups that are offering their solutions and services, which are optimized to run🏃🏻on Azure. The solution catalog spans several industry categories:
Open-source container platforms
Virtual machine images
Databases🛢
Application build and deployment software
Developer tools🛠
Threat detection 🛡
Blockchain🔗
Internet of Things (IoT) 📲is the ability for devices to garner and then relay information for data analysis. There are many services that can assist and drive end-to-end solutions for IoT on Azure. Two of the core Azure IoT service types are:
IoT 📲 Central is a fully managed global IoT software as a service (SaaS) solution that makes it easy to connect, monitor, and manage your IoT assets at scale⚖️.
IoT 📲 Hub is a managed service hosted in the cloud☁️ that acts as a central message hub for bi-directional communication between your IoT application and the devices it manages. You can use Azure IoT Hub to build IoT solutions with reliable and secure communications between millions of IoT devices and a cloud☁️-hosted solution backend.
IoT📲 Edge is the technology from Microsoft for building Internet of Things (IoT) solutions that utilize Edge Compute. IoT Edge extends IoT Hub. Analyze device data locally instead of in the cloud to send less data to the cloud☁️, react to events quickly, and operate offline.
Big data and analytics – Data comes in all types of forms and formats. When we talk about big data, we’re referring to large volumes of data.
Azure Synapse Analytics is a limitless analytics service that brings together enterprise data warehousing and big data analytics.
Azure HDInsight is a fully managed, open-source analytics service for enterprises. It is a cloud☁️ service that makes it easier, faster, and more cost-effective to process massive amounts of data. HDInsight supports open-source frameworks and create cluster types:
Apache Spark ⭐️
Apache Hadoop 🐘
Apache Kafka
Apache HBase
Apache Storm🌧
Machine Learning Services
Microsoft Azure Databricks🧱 provides data science and data engineering teams with a fast, easy and collaborative Spark-based platform on Azure. It gives Azure users a single platform for Big Data processing and Machine Learning.
Artificial Intelligence (AI) 🧠is the creation of software that imitates human behaviors and capabilities. Key🔑 elements include:
Machine learning – This is often the foundation for an AI system, and is the way we “teach” a computer in model to make prediction and draw conclusions from data.
Anomaly detection – The capability to automatically detect errors or unusual activity in a system.
Computer vision👓 – The capability of software to interpret the world visually through cameras, video, and images.
Natural language processing – The capability for a computer to interpret written or spoken language and respond in kind.
Conversational AI – The capability of a software “agent” to participate in a conversation.
Azure Machine Learningservice is a cloud-based☁️ platform for creating, managing, and publishing machine learning models. Azure Machine Learning provides the following features and capabilities:
Automated machine learning
Azure Machine Learning designer
Data and compute🖥 management
Pipelines
Azure Machine Learning studio is a web 🕸 portal for data scientist developers in Azure Machine Learning. The studio combines no-code and code-first experiences for an inclusive data science platform.
Serverless computing lets you run🏃🏻 application code without creating, configuring, or maintaining a server. Azure has two implementations of serverless compute🖥:
Azure Functions, which can execute code in almost any modern language.
Azure Logic Apps, which are designed in a web-based designer and can execute logic triggered by Azure services without writing any code.
Azure Event Grid allows you to easily build applications with event-based architectures. Event Grid has built-in support for events coming from Azure services, like storage🗄 blobs and resource groups.
“DevOps brings together people, processes, and technology, automating software delivery to provide continuous value to your users.”
Azure DevOps Services allows you to create build and release pipelines that provide CI/CD (continuous integration, delivery, and deployment) for your applications.
Azure DevOps – (SaaS) platform from Microsoft that provides an end-to -end DevOps toolchain⛓ for developing and deploying software. It also integrates with most leading tools🛠 on the market and is a great option for orchestrating a DevOps toolchain⛓.
Azure DevTest Labs🧪 – (PaaS) enables developers on teams to efficiently self-manage virtual machines (VMs. DevTest Labs🧪 creates labs 🧪 consisting of pre-configured bases or Azure Resource Manager templates.
Azure management options
You can configure and manage Azure using a broad range of tools🛠 and platforms. Tools🛠 that are commonly used for day-to-day management and interaction include:
Azure portal for interacting with Azure via a Graphical User Interface (GUI)
Azure PowerShell⚡️🐚 cross-platform version of PowerShell⚡️🐚 that enables you to connect to your Azure subscription and manage resources.
Azure Command-Line Interface (CLI) cross-platform command-line program that connects to Azure and executes administrative commands
Azure mobile 📱 app access, manage, and monitor 🎛 all your Azure accounts and resources from your iOS 📱 or Android phone or tablet.
Azure SDKs for a range of languages and frameworks, and REST 😴 APIs manage and control Azure resources programmatically.
Azure Advisor is a free service built into Azure that provides recommendations on high availability, security🔒, performance, operational excellence, and cost. Advisor analyzes your deployed services and looks for ways to improve your environment across each of these areas.
“Don’t worry about a thing Cause every little thing gonna be alright”
Security🔒, Privacy🤫, Compliance
Azure Advisor Security🔒 Assistance.
Azure Advisor Security🔒 Assistance integrates with Security🔒 Center.
Provide best practice security🔒 recommendations.
Azure Advisor Security🔒 Assistance helps prevent, detect, and respond to security🔒 threats.
You or your team should be using this tool every day to get the latest security🔒 recommendations.
Configuration of this tool 🔧, the amount of information it is gathering, the type of information it is gathering, is controlled through Security🔒 Center.
Securing Azure Virtual Networks
Network Security🔒 Groups (NSGs) – filter traffic🚦.
NSG has an inbound list and an outbound list.
Attached to subnets or network cards
Each NSG could be linked to multiple resources
NSG are stateful.
Application Security🔒 Groups – allow us to reference a group of resources
Used as even a source or destination of traffic🚦.
They do not replace network security🔒 groups.
Enhance them network security🔒 groups are still required.
When working with application security🔒 groups,
create the application security🔒 group
link the application security🔒 group to a resource
use the application security🔒 group when working with network security🔒 groups.
Azure Firewall🔥 is a stateful firewall🔥 service and highly available solution provided by Azure. It’s a virtual appliance configured at the virtual network level. It protects access to your virtual networks. Features of Azure Firewall🔥 include:
Threat intelligence. 🧠
It supports both outbound and inbound NATing
Integrates with Azure Monitor 🎛
Network traffic🚦filtering rules
Unlimited in scale⚖️
Azure DDos protection provides DDoS mitigation for networks and applications.
Always on as a service.
Provides protection all the way up to the application layer.
Integrates Azure Monitor 🎛 for reporting services.
Features offered by Azure DDoS protection include:
Multi‑layered support, so protection from layer 4 attacks up to layer 7 attacks.
Attack analytics. So, we can get reports on attacks in progress, as well as post attack reports
Scale⚖️ and elasticity
Provides protection against unplanned costs💰.
Azure DDoS comes in two different service tiers, basic and standard.
Azure Web Application Firewall🔥 is designed to publish your applications to the outside world 🌎 , whether they’re in Azure or on‑premises, and lures bound traffic🚦 towards them.
Forced tunneling allows the control of flow of internet‑bound traffic🚦.
Security🔒 Scenarios
Control Internet traffic🚦 – User defined routes, Azure FW 🔥 or marketplace device
Azure hosted SQL Server – NSGs
VPN – Forced tunneling
Azure identity services
Identity services will help us in the authentication 🔐and authorization👮🏽♂️ of our users. Authentication works hand in hand with authorization.
Authentication🔐 – The act of proving who or what something is
Authorization 👮🏽♂️ – Granting the correct level of access to a resource or service
In Azure, authentication🔐 is provided by Azure AD and authorization is provided by role‑based access control.
Azure Active Directory is a cloud-based identity service used in Azure. It used to authenticate and authorize users. When we think Azure Active Directory, think single sign on. Azure Active Directory is not to be equivalent of Active Directory Domain Services used on-premise.
Active Directory Domains Services – full Active Directory Domain Service that we’ve used for years on‑premise.
Azure AD Domain Services (PaaS)- introduced to make it easier to migrate legacy applications as it supports both NTLM and Kerberos for authentication🔐. also supports Group Policies, trust🤝 relationships, as well as several over domain service features.
Azure AD Connect as being like a synchronization tool.
Multi‑factor authentication involves providing several pieces of information to prove who you are. Microsoft strongly recommends that we use multi‑factor authentication.
Azure Security🔒 Center reports our complying status against certain standards.
It provides continuous assessment of existing and new services that we deploy, it also provides threat protection for both infrastructure and Platform as a Service services.
Azure Key 🔑 Vault is a service we can use to protect our secrets. Azure Key 🔑 Vault uses hardware security🔒 modules. These hardware security🔒 modules have been validated to support the latest Federal Information Processing Standards.
Azure Information Protection (AIP) to classify documents 📃 and emails 📧. AIP applies Labels to documents 📃. Labeled documents 📃 can be protected. There are two sides to Azure Information Protection
These classifications come in the form of metadata that can be attached with a header or added as watermarks to the document you’re trying to protect. Once classified, then the documents can be protected.
Classification of Documents. 📃
Azure uses Azure Rights Management to encrypt the documents using Rights Managements templates.
Azure Advanced Threat Protection 🛡 (Azure ATP) is a cloud☁️-based security🔒 solution that identifies, detects, and helps you investigate advanced threats, compromised identities, and malicious insider actions directed at your organization. Azure ATP 🛡 portal allows you to create your Azure ATP 🛡 instance, and view the data received from Azure ATP🛡 sensors.
Azure ATP 🛡sensors are installed directly on your domain controllers. The sensor monitors domain controller traffic🚦 without requiring a dedicated server or configuring port mirroring.
Azure ATP cloud☁️ service runs on Azure infrastructure and is currently deployed in the United States, Europe, and Asia. Azure ATP cloud☁️ service is connected to Microsoft’s intelligent security🔒 graph.
Azure Policy is a collection of rules. Each policy we create is assigned to a scope, such as an Azure subscription. When using Azure Policy, we create a policy definition, a policy assignment, and policy parameters,
When we create Azure policies, they can be used by themselves or they can be used with initiatives. Initiatives are a collection of policies. To use initiatives, we create an initiative definition, an initiative assignment, and initiative parameters
Role Based Access Control (RBAC) is used daily by your organization. It’s central to access control in Azure. Azure provides shared access. RBAC is made up of several different components
Roles are groups of permissions that are needed to perform different administrative actions in Azure. We then assign role members before configuring a scope for the role.
Scope details where a role can be used. There are many built‑in roles, each giving different sets of permissions, but three built‑in roles are used more than any other.
Three used most often roles are:
Owner role full control of that resource, including the ability to assign other users and group access.
Contributor role allows you to do everything except manage permissions.
Reader📖 role. This role is read‑only
Always follow the principle of least privilege.
Locks🔒 – prevent deletions or editing of resource groups and their content Two types Locks 🔒 are Read‑only and Delete.
If you make a resource group read‑only, then all the resources in there can be accessed, but no new resources can be added to the resource group or removed from the resource group.
Delete, then no resources can be deleted from the resource group, but new resources can be added.
Azure Blueprints – advanced way of orchestrating the deployment of resource templates and artifacts.
Blueprints maintain a relationship between themselves and the resources that they deployed.
Blueprints include Azure policy and initiatives as well as artifacts such as roles.
To use Blueprints, we require a Blueprint definition, we Publish the Blueprint, and then Assign it to a scope.
Blueprint definition
Resource groups can be defined and created
Azure policy can be included to enforce compliance
Azure resource manager templates can be included to deploy resources
Roles can be assigned to resources that blueprints have created
Azure Monitor to collect and analyze metric information both on premise and in Azure
Azure Service Health that we can use to see the health status of the Azure services
Personalized dashboards
Configurable alerts🔔
Guidance and Support
Service Trust🤝 Portal (STP) hosts the Compliance Manager service and is the Microsoft public site for publishing audit reports and other compliance-related information relevant to Microsoft’s cloud☁️ services.
ISO
SOC
NIST
FedRAMP
GDPR
Microsoft Privacy🤫 Statement explains what personal data Microsoft processes, how Microsoft processes it, and for what purposes.
Microsoft Trust🤝 Center is a website resource containing information and details about how Microsoft implements and supports security🔒, Privacy🤫, compliance, and transparency in all Microsoft cloud☁️ products and services.
In-depth information about security🔒, Privacy🤫, compliance offerings, policies, features, and practices across Microsoft cloud☁️ products.
Recommended resources in the form of a curated list of the most applicable and widely used resources for each topic.
Information specific to key🔑 organizational roles, including business managers, tenant admins or data security🔒 teams, risk assessment and Privacy🤫 officers, and legal compliance teams.
Cross-company document search, which is coming soon and will enable existing cloud☁️ service customers to search the Service Trust🤝 Portal.
Direct guidance and support for when you can’t find what you’re looking for.
Compliance Manager is a workflow-based risk assessment dashboard within the Trust🤝 Portal that enables you to track, assign, and verify your organization’s regulatory compliance activities related to Microsoft professional services and Microsoft cloud☁️ services such as Microsoft 365, Dynamics 365, and Azure.
Compliance Manager provides the following features:
Detailed information provided by Microsoft to auditors and regulators (ISO 27001, ISO 27018, and NIST).
Compliance with regulations (HIPAA).
An organization’s self-assessment on compliance with these standards and regulations.
Enables you to assign, track, and record compliance and assessment-related activities
Provides a Compliance Score to help you track your progress and prioritize auditing
Provides a secure repository in which to upload and manage evidence and other artifacts
Produces richly detailed reports which can be provided to auditors and regulators
Special Azure regions exist for compliance and legal reasons. These regions are not generally available, and you have to apply to Microsoft if you want to use one of these special regions.
US 🇺🇸 Gov regions support US government agencies (US Gov Virginia and US Gov Iowa)
China 🇨🇳special regions. China East, China North. (Partnership with 21Vianet)
Germany 🇩🇪 regions. Germany Central and German Northeast. (compliant with German data laws)
There are two types of subscription boundaries that you can use, including:
Azure subscriptions provide you with authenticated and authorized access to Azure products and services and allows you to provision resources. An Azure subscription is a logical unit of Azure services that links to an Azure account, which is an identity in Azure Active Directory (Azure AD) or in a directory that an Azure AD trusts🤝.
An account can have one subscription or multiple subscriptions that have different billing models and to which you apply different access-management policies.
Billing boundary. This subscription type determines how an Azure account is billed for using Azure.
Access control boundary. Azure will apply access-management policies at the subscription level, and you can create separate subscriptions to reflect different organizational structures. An example is that within a business, you have different departments to which you apply distinct Azure subscription policies.
The organizing structure for resources in Azure has four levels: management groups, subscriptions, resource groups, and resources. The following image shows the relationship of these levels i.e. the hierarchy of organization for the various objects
Management groups:
Allow you to apply governance conditions (access & policies) a level of scope above subscriptions
These are containers that help you manage access, policy, and compliance for multiple subscriptions. The resources and subscriptions assigned to a management group automatically inherit the conditions applied to the management group.
Azure offers three main types of subscriptions:
A free account
Pay-As-You-Go
Member offers
There are three main customer types on which the available purchasing options for Azure products and services is contingent, including:
Enterprise
Web 🕸 direct
Cloud☁️ Solution Provider
Options for purchasing Azure products and services
Pay-As-You-Go Subscriptions
Open Licensing
Enterprise Agreements
Purchase Directly through a Cloud☁️ Solution Provider (CSP)
Azure free account
The Azure free account includes free access to popular Azure products for 12 months, a credit to spend for the first 30 days, and access to more than 25 products that are always free.
Factors affecting costs💰
Resource type:
When you provision an Azure resource i.e. Compute🖥, Storage🗄, and Networking, Azure creates one or more-meter instances for that resource. The meters track the resources’ usage, and each meter generates a usage record that is used to calculate your bill.
Services: Azure usage rates and billing periods can differ between Enterprise, Web🕸 Direct, and Cloud☁️ Solution Provider (CSP) customers.
Location:
The Azure infrastructure is globally distributed, and usage costs💰 might vary between locations that offer Azure products, services, and resources.
All inbound or ingress data transfers to Azure data centers from on-premises environments are free. However, outbound data transfers (except in few cases like backup recovery) incur charges
Zones for billing purposes
A Zone is a geographical grouping of Azure Regions for billing purposes. the following Zones exist and include the sample regions as listed below:
Zone 1 – West US, East US 🇺🇸,Canada West 🇨🇦,West Europe🇪🇺,France Central 🇫🇷 and others
Zone 2 – Australia Central 🇦🇺, Japan West 🇯🇵 , Central India 🇮🇳 , Korea South 🇰🇷 and others
Zone 3 – Brazil South🇧🇷
DE Zone 1 – Germany Central, Germany Northeast 🇩🇪
Pricing Calculator 🧮
The Pricing Calculator 🧮 is a tool that helps you estimate the cost of Azure products. It displays Azure products in categories, and you choose the Azure products you need and configure them according to your specific requirements. Azure then provides a detailed estimate of the costs💰 associated with your selections and configurations.
Total Cost of Ownership Calculator
The Total Cost of Ownership Calculator is a tool that you use to estimate cost savings you can realize by migrating to Azure. To use the TCO calculator, complete the three steps that the following sections explain.
Define your workloads
Adjust assumptions
View the report
Best Practices for Minimizing Azure Costs💰
Shut down unused resources
Right-size underused resources
Configure autoscaling
Reserved instances pre‑pay for resources at a discounted rate.
Azure cost management provides a set of tools🛠 for monitoring🎛, allocating, and optimizing your Azure costs💰. The main features of the Azure Cost Management toolset include:
Reporting
Data enrichment
Budgets
Alerting 🔔
Recommendations
Price
Quotas. place around the resources and the amount of resources that you’re using.
Spending limits as your approaching that spending limit, you won’t be able to deploy more resources and not going to go over a budget.
Azure Hybrid Benefit Migrate your workloads to Azure, the best cloud☁️ for Windows Server and SQL Server
Tags🏷 when deploying resources in Azure, you will want to tag your resources. You can use this to identify resources for chargeback in your organization.
SLAs for Azure products or services
An SLA defines performance targets for an Azure product or service. The performance targets that an SLA defines are specific to each Azure product and service.
SLAs describe Microsoft’s commitment to providing Azure customers with certain performance standards.
There are SLAs for individual Azure products and services.
SLAs also specify what happens if a service or product fails to perform to a governing SLA’s specification.
Service Credits
SLAs also describe how Microsoft will respond if an Azure product or service fails to perform to its governing SLA’s specification.
Application SLA
Azure customers can use SLAs to evaluate how their Azure solutions meet their business requirements and the needs of their clients and users. By creating your own SLAs, you can set performance targets to suit your specific Azure application. When creating an Application SLA consider the following:
Identify workloads.
Plan for usage patterns.
Establish availability metrics
Establish recovery metrics
Implement resiliency strategies.
Build availability requirements into your design.
Composite SLA
When combining SLAs across different service offerings, the resultant SLA is a called a Composite SLA. The resulting composite SLA can provide higher or lower uptime 🕰 values, depending on your application architecture.
Service lifecycle in Azure
Microsoft offers previews of Azure services, features, and functionality for evaluation purposes. With Azure Previews, you can test pre-release features, products, services, software, and even regions.
There are two categories of preview that are available:
Private preview – An Azure feature is available to certain Azure customers for evaluation purposes.
Public preview – An Azure feature is available to all Azure customers for evaluation purposes.
General availability
Once a feature is evaluated and tested successfully, the feature may be made available for all Azure customers. A feature released to all Azure customers typically goes to General Availability or GA.
The Azure updates page provides the latest updates to Azure products, services, and features, as well as product roadmaps and announcements.
“On the road again…I just can’t wait to get on the road again”
“You take the blue pill 💊— the story ends, you wake up in your bed 🛌 and believe whatever you want to believe. You take the red pill 💊 — you stay in Wonderland and I show you how deep the rabbit🐰 hole goes.”
Last week, we hopped on board the Nebuchadnezzar🚀 and traveled through the cosmos🌌 to Microsoft’s multi-model NoSQL Solution. So, this week we decided to go further down the “rabbit🐰 hole” and explore the wondrous land of Microsoft’s NoSQL Azure solutions as well as Graph📈 database. We would once again revisit with Cosmos DB🪐 exploring all 5 APIs. In addition, we would have brief journey with Azure Storage (Table), Azure Data Lake (Gen2), and Azure’s managed data analytics service for real-time analysis (ADLS), and Azure Data Explorer (ADX). Then for an encore we would venture into the world’s🌎 most popular Graph📈 database Neo4J
First, playing the role as our leader “Morpheus” in our first mission would be featured Pluralsight author and premier trainer Reza Salehi through his recently released Pluralsight course Implementing NoSQL Databases in Microsoft Azure . Reza doesn’t take us quite as deep in the weeds 🌾 with Cosmos DB🪐 as Lenni Lobel’sLearning Azure Cosmos DB🪐 Pluralsight course but that is because his course covers a wide range of topics in the Azure NoSQL ecosystem. Reza provides us a very practical real-world🌎 scenario like migrating from MongoDB🍃Atlas to Cosmos DB🪐(MongoDB🍃 API) and he also covers the Cassandra API which was omitted from Lenni’s offerings. In addition, Reza spends some time giving a comprehensive overview on Azure Storage (Table) and introduces us to ADLS and ADX all of which were all new to our learnings.
In the introduction of the course, Reza gives us a brief history on NoSQL which apparently has existed since the 1960s! It just wasn’t called NoSQL. He then gives us his definition of NoSQL and emphasizes its main goal to provide horizontal scalability, availability and optimal pricing. Reza’s mentions an interesting factoid that Azure NoSQL solitons have been used by Microsoft for about decade through Skype, Xbox 🎮, Office 365 🧩 neither of which scaled very well with a traditional relational database.
Next, he discusses Azure Table Storage (soon to be deprecated and replaced by Cosmos DB🪐 Table API). Azure Table storage can store large amounts of structured and non-relational data (datasets that don’t require complex joins, foreign keys🔑 or stored procedures) cost effectively. In addition, It is durable and highly available, secure, and massively scalable⚖️. A table is basically a collection of entities with no schema enforced. An entity is a set of properties (maximum of 252) similar to a row in table in a relational database. A property is a name-value pair. Three main system properties that must exist with each entity are a partition Key🔑 , row key🔑 and a timestamp. In the case of a Partition Key🔑 and a Row key🔑 the application is responsible for inserting and updating these values whereas the Timestamp is managed by Azure Table Storage and this value is immutable. Azure automatically manages the partitions and the underline storage, so as the data in your table grows, the data in your table is divided into different partitions. This allows for faster query performance⚡️ of entities with the same partition key🔑 and for atomic transactions on inserts and updates.
Next on the agenda was Microsoft’s globally distributed, multi-model database service better known Cosmos DB🪐. Again, we had been down this road just last week but just like re-watching the first Matrix movie🎞 I was more than happy 😊 to do so.
As a nice review, Reza reiterated some of the core Cosmos DB🪐 concepts like Global distribution, Multi-homing, Data Consistency Levels, Time-to-live (TTL), and Data Partitioning. All of which are included with of all five flavors or APIs in Cosmos DB🪐 because at the end of the day each API is just another container to the Cosmos DB🪐. Some of the highlights included:
Global distribution
· Cosmos DB🪐 allows you to add or remove any of the azure regions to your cosmos account at any time with a click of a button.
· Cosmos DB🪐 will seamlessly replicate your data to all the region’s associate ID with your cosmos account.
· The multi homing capability of Cosmos DB🪐 allows your application to be highly available.
Multi-homing APIs
· Your application is aware of the nearest region and sends requests to that region.
· Nearest region is identified without any configuration changes
· When a new region is added or removed, the connection string stays the same
Time-to-live (TTL)
• You can set the expiry time (TTL) on Cosmos DB data items
• Cosmos DB🪐 will automatically remove the items after this time period, since the last modification time ⏰
Cosmos DB🪐 Consistency Levels
• Cosmos DB🪐 offers five consistency levels to choose from:
· A logical partition consists of a set of items that have the same partition key🔑.
· Data that’s added to the container is automatically partitioned across a set of logical partitions.
· Logical partitions are mapped to physical partitions that are distributed among several machines.
· Throughput provisioned for container, is divided evenly among physical partitions.
Then Reza’s breaks down each of the 5 Cosmos DBs🪐 APIs in separate modules. But at the risk, of being redundant from last week’s submission, we will just focus on the MongoDB🍃 API and the Cassandra API as we covered the other APIs in-depth last week. I will make one important point for all APIs that you are working with that is you must choose an appropriate partition key🔑. As rule of thumb 👍, an ideal Partition key🔑 should have a wide range of values, so your data is evenly spread across logical partitions.
MongoDB🍃 API in Cosmos DB🪐 supports the popular MongoDB🍃 Document database with absolutely no code changes other than a connection string to existing applications. It now supports up to MongoDB 🍃version 3.6.
During this module, Reza provides us with a very practical real world 🌎 scenario migrating from MongoDB🍃Atlas to Cosmos DB🪐 (MongoDB🍃 API). We were happy😊 to report that we were able to follow along easily and successfully migrate our own MongoDB🍃 Atlas collections to Cosmos DB🪐.
Important to note: Before starting a migration from MongoDB🍃 to Cosmos DB🪐, you should estimate the amount of throughput to provisioned for your azure cosmos databases on collections and of course pick an optimal partition key🔑 for your data.
Next, we will focused on the Cassandra API in Cosmos DB🪐. This one admittedly, I was really looking forward too as it wasn’t in scope in our previous journey. Cosmos DB🪐 – Cassandra API can be used as the data store for apps written for Apache Cassandra. Just like for MongoDB🍃, existing Cassandra applications using CQLv4 compliant drivers, can easily communicate with the Cosmos DB🪐 Cassandra API. Making it easy to switch from Apache Cassandra to Cosmos DB🪐 Cassandra API with only requiring an update to the connection string. The familiar CQL, Cassandra client drivers, and Cassandra-based tools can all be used making for seamless migration with of course the benefits of Cosmos DB🪐 like
· No operations management (PaaS)
· Low latency reads and writes
· Use existing code and tools
· Throughput and storage elasticity
· Global distribution and availability
· Choice of five well-defined consistency levels
· Interact with Cosmos DB🪐 Cassandra API
Next we ventured on to new ground with Azure Data Lake Storage (ADLS). ADLS is a hyper-scale repository for big data analytic workloads. Azure Storage (Gen 2) is the foundation for building enterprise data lakes on ADLS. ADLS supports hundreds of gigabits of throughput and manages massive amounts of data. Some Key features of ADLS include:
· Hadoop compatible – manage data same as Hadoop HDFS
· POSIX permissions – supports ACL and POSIX file permissions
Last but certainly not least on this Journey with Reza was an introduction to Azure Data Explorer (ADX) a fast and highly scalable⚖️ data exploration service for log and telemetry data. ADX is designed to ingest data from devices like websites, logs and more. These ingestion sources come natively from Azure Event Hub, IoT hub and Blob Storage. Data is then stored in highly scalable⚖️ database and analytics are performed using Kusto Query Language (KQL). ADX can be provisioned with Azure CLI, PowerShell, C# (NuGet package), Python 🐍 SDK and the ARM template. One of the key features of ADS is Anomaly Detection. ADX uses machine learning under the hood to find these anomalies. ADX also supports many data visualization tools like
· Kusto query language visualizations
· Azure Data Explorer dashboards (Web UI)
· Power BI connector
· Microsoft Excel connector
· ODBC connector
· Granfana (ADX plugin)
· Kibana Connector (using k2bridge)
· Tableau (via ODBC connector)
· Qlik (via ODBC connector)
· Sisense (via JDBC connector)
· Redash
ADX can easily integrate with other services like:
· Azure Data Factory
· Microsoft Flow
· Logic Apps
· Apache Spark Connector
· Azure Databricks
· CI/CD using Azure DevOps
I’ll show these people what you don’t want them to see. A world🌎 without rules and controls, without borders or boundaries. A world🌎 where anything is possible. -Neo
After spending much time in Cosmos DB🪐 and in particular the Graph📈Database API, I have become very intrigued by this type of NoSQL solution. The more I explored the more I coveted. I had a particular yearning to learn more about the world’s 🌎 most popular graph 📈database Neo4J. For those not aware of Neo4J its developed by Swedish 🇸🇪 Technology company sometimes referred to as Neo4J or Neo Technology. I guess it depends on the day of the week?
According to all accounts the name Neo” was named for Swedish 🇸🇪 pop artist and favorite of the Swedish🇸🇪 developers Linus “Neo” Ingelsbo, “4” (for version) and “J” for the Swedish🇸🇪 word “Jätteträd” which of course means “giant tree 🌳” because a tree 🌳 signifies the huge data structures that could now be stored in this amazing database product. But to me this story seems a bit curious.. With a database name like “Neo” and Querying language called “Cypher” and with Awesome Procedures On Cypher better known as APOC I somehow believe there is another story here..
In the introduction, Roland tells us the Who, What, When, Where, Why and How about graph📈 databases. A graph 📈consists of nodes or vertices which are connected by directional relationships or Edges. A node represents an entity. An entity is typically something in the real world🌎 like a customer, an order or a person A collection of nodes and relationships together is called a graph 📈. Graph📈databases are very mind friendly compared to other data storage technologies because graphs📈 act a lot like how the human brain🧠 works. It’s easier to think of the data structure and also easier to write queries. These patterns are much like the patterns of the brain🧠 uses to fetch data or retrieve memories.
Graph 📈 Databases are all about relationships and thus are very strong in storing and retrieving highly related data. They are also very performant during querying even with large number of nodes like in the millions. They offer great flexibility as like all NoSQL databases it doesn’t require a fixed schema. In addition, they are quite agile as you can add or delete nodes and property of nodes without affecting already stored nodes and it’s extensible supporting multiple query languages
After a comprehensive overview with graph📈 database, Roland dives right into Neo4J the leader in Graph 📈database. Unlike document databases, Neo4j is ACID compliant which means that all data modification is done within a transaction. If something goes wrong, Neo4j will simply roll back to a state where the data was reliable.
Neo4J is Java☕️ based which allows you to install it on multiple platforms like Windows, Linux, and OS X. Neo4j can scale⚖️ up as it can easily adjust to a hardware changes i.e. adding more physical memory in which it will automatically add more nodes in the cache. Neo4J can also scale ⚖️ out like most NoSQL Solutions i.e. adding more servers meaning it can distribute the load of transactions or create a highly available cluster in which a server will take over when the active one fails.
Since by definition Neo4J is a graph📈 database, it’s all about relationships and nodes. Both nodes and relationships are equally as important. Nodes are schema-less entities with properties (key-value pairs) which are always strings. Relationship connects a node to another node. Just like nodes, they also can contain properties that also support indexing.
Next, Roland discusses Querying Data with Cypher which is the most powerful⚡️of Query languages supported by Neo4J. Cypher was developed and optimized for Neo4j and for graph📈 databases. Cypher is a very fluid language meaning it continuously changes with each release. The good 😊 news is all major releases are backwards compatible to all old versions of the language. It’s very different for SQL so there is a bit of a learning curve. However, it’s not as steep as a learning curve you would imagine because Cypher uses patterns to match the data in the database very much how the brain🧠 works. That and Neo4J Desktop has intellisense. 😊
As example to demonstrate the query language and CRUD we worked with a very cool Dr. Who graph 📈database filled multiple nodes with Actors, Roles, Episodes, Villains and their given relationships. To begin we started with “R” or Reads part of CRUD learning the MATCH command
Below is some MATCH – RETURN syntax:
MATCH (:Actor{name:’Matt Smith’}) -[:PLAYED]->(c:Character) RETURN c.name as name
MATCH (actors:Actor)-[:REGENERATED_TO]-> (others) RETURN actors.name, others.name
MATCH (:Character{name:’Doctor’})<-[:ENEMY_OF]-(:Character)-[:COMES_FROM]->(p:Planet) RETURN p.name as Planet, count(p) AS Count
MATCH (:Actor{name:’Matt Smith’})-[:APPEARED_IN]-> (ep:Episode)<-[:APPEARED_IN]- (:Character{name:’Amy Pond’}),(ep) <-[:APPEARED_IN]-(enemies:Character)<-[:ENEMY_OF]-(Character{name:’Doctor’}) RETURN ep AS Episode, collect(enemies.name) AS Enemies;
Further, Roland discussed the WHERE Clause and ORDER BY Clauses which are very similar to ANSI SQL. Then he converses about other Cypher syntax like:
SKIP – which skips the number of result items you specify.
LIMIT – which limits the numbers of items returned.
With UNION which allows to connect two queries together and generate one result set.
Then he ends the module conferring on Scalar functions like TOINT,
LENGTH, REDUCE, FILTER, ROUND, and SUBSTRING.
Then he reviews two of his favorite some advanced query features like COMPANION_OF and SHORTESTPATH.
Continuing on with C,U,D in CRUD, we played with the CREATE, MATCH WITH SET and MATCH DELETE
Below is some Syntax:
CREATE p= (:Actor{name:’Peter Capaldi’})-[:APPEARED_IN]->(:Episode{name:’The Time of The Doctor’}) RETURN p
MATCH (Matt:Actor{name: ‘Matt Smith’}}
DELETE matt
MATCH (Matt:Actor{name: ‘Matt Smith’}}
SET matt.salary = 1000
Then looking at MERGE and FOREACH with the below syntax as example:
MERGE (peter:Actor{name: ‘Peter Capaldi’}) RETURN peter
Match p =(actors:Actor)-[r:PLAYED]->others)
WHERE actors.salary > 10000
FOREACH (n IN nodes(p)| set n.done = true)
As we continued our journey with Neo4J, we reconnoitered on Indexes and Constraints. Indexes are only good for data retrieval. So, if your application performs lots of writes it’s probably best to avoid them. As for constraints, the unique constraint is currently the only constraint available in Neo4j. That is why this is often called just constraint. Lastly, in the module we reviewed Importing CSV which makes importing data from other sources a breeze. It enables you to import data into a Neo4j’s database from many sources. CSV files can be loaded from the local file system, as well as remote locations. Cypher has a LOAD CSV statement, which is used together with CREATE and/or MERGE.
Finally, Roland reviewed Neo4j’s APIs which was a little bit out of our lexicon but interesting nonetheless. Neo4j supports two API types out of the box. The traditional REST and their proprietary Bolt⚡️. The advantage of Bolt⚡️is mainly performance. Bolt⚡️ doesn’t have the HTTP overhead, and it uses a binary format instead of text to return data. For both the REST and Bolt APIs Roland provides C# code sample that can be run with NuGet packages in Visual Studio my new favorite IDE.
Ever have that feeling where you’re not sure if you’re awake or dreaming?
Below are some topics I am considering for my learnings next week:
“Now let me welcome everybody to the Wild, Wild West 🤠. A state database that’s untouchable like Eliot Ness.” So, after spending a good concentrated week in the “humongous” document database world better known as the popular MongoDB🍃, it only made sense to continue our Jack Kerouac-like adventures through the universe 🌌 of “Not only SQL” databases.
“So many roads, so many detours. So many choices, so many mistakes.” -Carrie Bradshaw
But with so many Document databases, Table and Key-value stores, Columnar and Graph databases to choose from in the NoSQL universe, where shall we go? Well, after a brief deliberation, we turned to the one place that empowers every person and every organization on the planet to achieve more. That’s right, Microsoft! Besides we haven’t been giving Mr. Softy enough love ❤️ in our travels. So, we figured we would take a stab and see what MSFT had to offer. Oh boy, did we hit eureka with Microsoft’s Cosmos DB🪐!
For those not familiar with Microsoft’s Cosmos DB🪐 it was released for GA in 2017. The solution had morphed out of the Azure DocumentDB (the “Un-cola”🥤of document databases of its day) which was initially released in 2014. During the time of its inception, Azure DocumentDB was the only NoSQL Cloud☁️ solution (MongoDB🍃 Atlas☁️ was released two years later in 2016) but its popularity was still limited. Fortunately, MSFT saw the “forest 🌲🌲🌲through the trees🌳” or I shall I say the planets🪐 through the stars ✨ and knew there was a lot more to NoSQL then just some JSON and bunch of curly braces. So, they “pimped up” Azure DocumentDB and gave us the Swiss🇨🇭 Army knives of all NoSQL solutions through their rebranded offering Cosmos DB🪐
Cosmos DB 🪐 is multi-model NoSQL Database as a Service (NDaaS) that manages data at planetary 🌎 scale ⚖️! Huh? In other words, Cosmos DB🪐 supports 6 different NoSQL solutions through the beauty of APIs (Application Program Interfaces). Yes, you read that correctly. Six! Cosmos DB🪐 supports the SQL API which was originally intended to be used with aforementioned Azure DocumentDB which uses the friendly SQL query language, the MongoDB🍃 API (For all the JSON fans), Cassandra (Columnar database), Azure Table Storage (Table) and etcd (Key Value Store) and last but certainly not least the Gremlin👹 API (Graph database).
Cosmos DB🪐 provides virtually unlimited scale ⚖️ through both storage and throughput and it automatically manages the growth of the data with server-side horizontal partitioning.
So, no worrying about adding more nodes or shards. …And that’s not all! Cosmos DB🪐 does all the heavy lifting 🏋🏻♀️ with automatic global distribution and server-side partitioning for painless management over the scale and growth of your database. Not to mention, offers a 99.999% SLA when data is distributed across multi-regions 🌎 (Only a mere four 9s when you stick to a single region).
Yes, you read that right, too. 99.999% guarantee! Not just on availability… No, No, No… but five 9s on latency, throughput, and consistency as well!
Ok, so now I sound like a MSFT fanboy. Perhaps? So now, we were fully percolating ☕️ with excitement who will guide us through such amazing innovation? Well, we found just the right tour guide in a Native New Yorker Lenni Lobel. Through his melodious 🎶 voice and over 5 decades of experience in IT, Lenni takes us through an amazing journey through Cosmos DB🪐 with his Plural sight course Learning Azure Cosmos DB🪐
In the introduction, Lenni gives his us his interpretation on NoSQL which answers the common problem of 3Vs in regards to data and the roots of Cosmos DB🪐 which we touched on earlier. Lenni then explains how the Cosmos DB🪐 engine is an atom-record-sequence (ARS) based system. In other words the database engine of Cosmos DB🪐 is capable of efficiently translating and projecting multiple data models by leveraging ARS. Still confused? Don’t be. In more simplistic terms, under the covers Cosmos DB🪐 leverages the ARS framework to be able support multiple NoSQL technologies. It does this through APIs and then placing each of data models in separate schema-agnostic containers which is super cool 😎! Next, he discusses one of the cooler 😎 features of Cosmos DB🪐 “Automatic Indexing”. If you recall from our MongoDB travels one of the main takeaways was a strong emphasis on the need for indexes in MongoDB🍃. Well, in Cosmos DB🪐 you need not to worry. Cosmos DB🪐 does this for you automatically. The only main concern is choosing the right partition key🔑 on your container but you must choose wisely otherwise performance and cost will suffer.
Lenni further explains how one quantifies performance for data through Latency and throughput. In the world 🌎 of data, Latency is how long the data consumer waits for the data to be received from end to end. Whereas throughput is the performance of database itself. First, Mr. Lobel demonstrates how to provision throughput through Cosmos DB🪐 which provides predictable throughput to the database through a server-less approach measured in Request Units (RUs). RUs are a blended measure of computational cost CPU, memory, disk I/O, network I/O.
So, like most server-less approaches you don’t need to worry about provisioning hardware to scale ⚖️ your workloads. You just need to properly allocate the right amount of RUs to a given container. The good news on RUs is that this setting is flexible. So it can be easily throttled up and down through the portal or even specify on an individual query level.
Please note: data writes are generally more expensive than data reads. The beauty of the RU approach is that you are guaranteed throughput and you can predict cost. You will even be notified through a friendly error message when your workloads exceed a certain threshold. There is an option to run your workloads in an “auto-pilot ✈️ mode” in which Cosmos DB🪐 will adjust the RUs to a given workload but beware this option could be quite costly so proceed with risk and discuss this option with MSFT before considering using it.
In effort of being fully transparent, unlike some of their competitors, Microsoft offers a Capacity Calculator So you can figure out exactly how much it will cost you to run your workloads (Reserved RU/sec per hour $0.008 for 100 RU/sec). The next import considerations in regards to throughput is Horizontal Partitioning. Some might regard, Horizontal Partitioning as strictly just for storage, but in fact it also massively impacts throughput.
“Yes, it’s understood that Partitioning and throughput are distinct concepts, but they’re symbiotic in terms of scale-out.”
Anyway, no need to fret… We just simply create a container and let Cosmos DB🪐 automatically manage these partitions for us behind the scenes (including the distribution of partitions within a given data center). However, keep in mind that we must choose a proper partition key🔑 otherwise we can have a rather unpleasant😞 and costly🤑 experience with Cosmos DB🪐. Luckily, there are several best practices around choosing the right partition key🔑. Personally, I like to stick to the rule of thumb 👍 to always choose a key🔑 with many distinct values like in 100s or 1000s. This can hopefully help avoid the dreaded Hot🔥 Partition
Please note: Partition keys 🔑 are immutable but there are documented workarounds on how to deal with changing this in case you find yourself in this scenario.
Now, that we have a good grasp on how Cosmos DB🪐 handles throughput and latency through RUs and horizontal partitioning but what if your application is global 🌎 and your primary data is located halfway around the world 🌍 ? Our performance could suffer tremendously… 😢
Cosmos DB🪐 handles such challenges with one of its most compelling features in the solution through Global Distribution of Data. Microsoft intuitively leverages the ubiquitousness of its global data centers and offers a Turnkey global distribution “Point-and-click” control so your data can seamlessly be geo-replicated across regions.
In cases, where you have multiple-masters or data writers, Cosmos DB🪐 offers three options to handle such conflicts:
Option 1: Last Writer Wins (default) based on the highest _ts property or any other numeric property) Conflict Resolver Property Write with higher valuer wins if blank than master with high _ts property wins
Option 2: Merge Procedure (Custom) – Based on stored procedure result
Option 3: Conflict feed (Offline resolution) Based Quorum majority
Whew 😅 … But what about data consistency? How do we ensure our data is consistent in all of our locations? Well once again, Cosmos DB🪐 does not disappoint supporting five different options. Of course, like life itself there is always tradeoffs. So, depending on your application needs. You will need to determine what’s the most important need for your application latency or availability? Below are the options based higher latency to lowest availability:
Strong – (No Dirty Reads) Higher latency on writes waiting for write to be written to Cosmos DB Quorum. Higher RU costs
Bounded Staleness – Dirty reads possible Bounded by time and updates which kind of like “Skunked🦨 beer🍺” You decide the level of freshness you can tolerate.
Session – (Default) No dirty reads for writers (read your own writes). Dirty Reads are possible for other users
Consistent Prefix – Dirty reads possible. Reads never see out-of-order writes. Never experience data returned out of order.
Eventual – Stale reads possible, No guaranteed order. Fastest
So, after focusing on these core concepts within Cosmos DB🪐, we were ready to dig our heels 👠 👠 right in and get this bad boy up and running 🏃🏻 . So after waiting about 15 minutes or so… we had our Cosmos DB🪐 fired up 🔥 and running in Azure… Not bad for a such complex piece of infrastructure. 😊
Next, we created a Container and then a Database and started our travels with the SQL API. Through the portal, We were easily able manually write some JSON documents and add them to our collection.
In addition, through Lenni’s brilliantly written .Net Core code samples, we were able to automate writing, Querying, and reading in bulk data. Further, we were able to easily adjust throughput and latency through the portal by tweaking the RUs and enabling multi-region replication. We were able to demonstrate this by re-running Lenni’s code after the changes
Although, getting Lenni’s code to work did take a little bit of troubleshooting with visual studio 2019 and a little bit of understanding how to fix the .Net SDK errors and some of Compilation errors NuGet from packages . All of which was out of our purview.. But needless to say we figured how to troubleshooted the NuGet Packages and modify some of the parameter’s in the code like _ID field and Cosmos DB🪐 Server and Cosmos DB master key 🔑.
We were able to enjoy the full experience of SQL API including the power⚡️ of using the familiar SQL query language and not to having to worrying about the all
db.collection.insertOne() this
and
db.collection.find(),
db.collection.UpdateOne()
db.collection.deleteOne()
that..
We also got to play with server‑side programming in Cosmos DB🪐 like the familiar concept of stored procedures, triggers, and user‑defined functions which in Cosmos DB🪐 are basically self‑contained JavaScript functions that are deployed to the database for execution. But one can always pretend like we are in the relational database world. 😊
Next we, got to test drive 🚙 the Data Migration tool 🛠 that allows you to import data from an existing data sources into Cosmos DB🪐.
From our past experiences, we have found Microsoft has gotten quite good at creating these type of tools 🧰. Cosmos DB🪐 Data Migration tool offers great support for many data sources like SQL Server, JSON files, CSV files, MongoDB, Azure Table storage, and others.
First, we used the UI to move data from Microsoft SQL Server 2016 and the popular example Adventureworks database to Cosmos DB🪐 and then later through the CLI (azcopy) from Azure Table storage.
Notably, Azure Table Storage is on the road map to be deprecated and automatically migrated to Cosmos DB🪐 but this was good exercise for those who can’t wait and want to take advantage such awesome platform today!
As a grand finale, we got to play with Graph Databases through the Gremlin 👹 API. As many of you might be aware, Graph databases are becoming excessively popular these days. Mostly because Data in the real world is naturally connected through relationships and Graph Databases do a better job managing when many complex relationships exist opposed to our traditional RDBMS.
Again, it’s worth noting that in the case of Cosmos DB🪐, it doesn’t really matter what data model you’re implementing because as we mentioned earlier it leverages the ARS framework. So as far as Cosmos DB🪐 concerned it’s just another container to manage and we get all the Horizontal partitioning, provisioned throughput, global distribution, indexing goodness 😊.
We were new to whole concept of Graph Databases so we were very excited to get some exposure here which looks to be a precursor for further explorations. The most important highlights of Graph database is understanding Vertex and Edge objects. These are basically just fancy schmancy words for Entities and Relationships. A Vertex is an entity and a Edge is a relationship between any two vertices respectively. Both can hold arbitrary key-value pairs 🔑🔑 and are the building blocks of a graph database.
Cosmos DB🪐 utilizes the Apache TinkerPop standard which uses Gremlin as a functional step-by-step language to create vertices and edges and stores the data as GraphSON or “Graphical JSON”.
In addition, Gremlin 👹 allows you to query the graph database by using simple transversals though a myriad of relationships or Edges. The more edges you add, the more relationships you define, and the more questions you can answer by running Gremlin👹 Queries. 😊
To further our learning Lenni once again gave us some nice demos using a fictitious company “Acme” and its relationships of employees, Airport terminals and Restaurants and another example using Comic Book hero’s which made playing along fun.
Below is some example of some Gremlin 👹 syntax language from our voyage.
When in comes to Graph databases the possibilities are endless. Some good use cases for Graph Database would be:
Complex Relationships – Many “many-to-many” relationships
Excessive JOINS
Analyze interconnected data relationships
Typical graph applications
Social networks
Recommendation Engines
In Cosmos DB🪐, it’s clear to see how a graph database is no different than any other key value data model. Graph database gets provisioned throughput, fully indexed, partitioned, and globally distributed just like a document collection in this SQL API or a table in the Table API
Cosmos DB🪐 will one day allow you to switch freely between different APIs and data models within the same account, and even over the same data set. So by adding this graph functionality to Cosmos DB🪐 Microsoft really hit ⚾️ this one out of the park 🏟!
Closing time …Every new beginning.. comes from some other beginning’s end
Below are some topics I am considering for my wonderings next week:
All aboard! This week our travels would take us on the railways far and high but before, we can hop on the knowledge express we had some unfinished business to attended too.
“Oh, I get by with a little help from my friends”
If you have been following my weekly submissions for the last few weeks I listed as future action item “create/configure a solution that leverages Python to stream market data and insert it into a relational database.“
Well last week, I found just the perfect solution. A true master piece by Data Scientist/Physicist extraordinaire AJ Pryor, Ph.D. AJ had created a brilliant multithreaded work of art that continuously queries market data from IEX and then writes it to a PostgreSQL database. In addition, he built a data visualization front-end that leverages Pandas and Bokeh so the application can run interactively through a standard web browser. It was like a dream come true! Except that the code was written like 3 years ago and referenced a deprecated API from IEX.
Ok, no problem. We will just simply modify AJ’s “Mona Lisa” to reference the new IEX API and off we will go. Well, what seemed like was a dream turned into a virtual nightmare. I spent most of last week spinning my wheels trying to get the code to work but to no avail. I even reached out to the community on Stack overflow but all I received was crickets..
As I was ready to cut my loses, but I reached out to a longtime good friend who happens to be all-star programmer and a fellow NY Yankees baseball enthusiast. Python wasn’t his specialty (he is really an amazing Java programmer) but he offered to take a look at the code when he had some time… So we set up a zoom call this past Sunday and I let his wizardry take over… After about hour or so he was in a state of flow and had a good pulse of what our maestro AJ’s work was all about. After a few modifications my good chum had the code working and humming along. I ran into a few hiccups along the way with the brokeh code, but my confidant just referred me to run some simpler syntax and then abracadabra… this masterpiece was now working on the Mac! As the new week started, I was still basking in the radiance of this great coding victory. So, I decided to be a bit ambitious and move this gem to the cloud which would be like the crème de la crème of our learnings thus far. Cloud, Python/Pandas, Streaming market data, and Postgres all wrapped up in one! Complete and utter awesomeness!
Now the question was for which cloud platform to go with? We were well versed in the compute area in all 3 of the major providers as a result of our learnings.
So with a flip of the coin ,we decided to go with Microsoft Azure. That and we had some free credits still available.
With sugar plum fairies dancing in our head, we spun up our Ubuntu Image and we followed along the well documented steps on AJ’s Github project
Now, we were now cooking with gasoline ! We cloned AJ’s Github repo, modified the code with our new changes, and executed the syntax and just as we were ready to declare victory… Stack overflow Error! Oh, the pain.
Fortunately I didn’t waste any time, I went right back to my ace in the hole but with some trepidation that I wasn’t being too much of irritant.
I explained my perplexing predicament and without hesitation my Fidus Achates offered some great trouble shooting tips and quite expeditiously we had the root cause pinpointed. For some peculiar reason, the formatting of URL that worked like a charm on the Mac was a dyspepsia on Ubuntu on Azure. It was certainly a mystery but one that can only be solved by simply rewriting the code.
So once again, my comrade in arms helped me through another quagmire. So, without further ado, may I introduce to you the one and only…
We’ll hit the stops along the way We only stop for the best
After feeling victorious after my own personal Battle of Carthage and with our little streaming market data saga out of our periphery it was to time to hit the rails…
Our first stop was messaging services which is all the rage now a days. There are so many choices with data messaging services out there.. So where to start with? We went with Google’s Pub/Sub which turned out to be a marvelous choice! To get enlightened with this solution, we went to Pluralsight where we found excellent course on Architecting Stream Processing Solutions Using Google Cloud Pub/Sub by Vitthal Srinivasan
Vitthal was a great conductor who navigated us through an excellent overview of Google’s impressive solution, uses cases, and even touched on a rather complex pricing structure in our first lesson. He then takes us deep into the weeds showing us how to create Topics,Publishers, and Subscribers. He goes on further by showing us how to leverage some other tremendous offerings in GCP like Cloud Functions, API & Services, and Storage.
Before this amazing course my only exposure was just limited to GCP’s Compute Engine so this was eye opening experience to see the great power that GCP had to offer! To round out the course, he showed us how to use GCP Pub/Sub with some client Libraries which was excellent tutorial on how to use Python with this awesome product. There was even two modules on how to integrate Google Hangout Chatbot with Pub/Sub but that required you to be a G Suite User. (There was free trial but skipped the set up and just watched the videos) Details on the work I did on Pub/Sub can be found at
“…When the Promise of a brave new world unfurled beneath a clear blue Sky”
“Forests, lakes, and rivers, clouds and winds, stars and flowers, stupendous glaciers and crystal snowflakes – every form of animate or inanimate existence, leaves its impress upon the soul of man.” — Orison Swett Marden
My journey for this week turned out to be a sort of potpourri of various technologies and solutions thanks to the wonderful folks at MSFT. After some heavy soul searching over the previous weekend, I decided that my time would be best spent this week on recreating the SQL Server 2016 with Always On environment (previously created several weeks back on AWSEC2) but in the MS Azure Cloud platform. The goal would be to better understand Azure and how it works. In addition, I would be able to compare and contrast both AWS EC2 vs. Azure VMs and be able to list both the pros and cons of these cloud providers.
But before I could get my head into the clouds I was still lingering around in the bamboo forests. This past weekend, I was presented with an interesting scenario to stream market data to pandas from the investors exchange (Thanks to my friend) . So after consulting with Mr. Google, I was pleasantly surprised to find that IEX offered an API that allows you to connect to there service and stream messages directly to Python and use Pandas for data visualization and analysis. Of course being the cheapskate that I am I signed up for a free account and off I went.
So I started tickling the keys, I produced a newly minted IEX Py script. After some brief testing, I started receiving an obscure error? Of course there was no documented solution on how to the address such an error..
So after some fruitless nonstop piping of several modules, I was still getting the same error. 🙁 After a moment of clarity of I deduced there was probably limitation on messages you can stream from the free IEX account..
So I took shot in the dark and decided to register for another account (under a different email address) this way I would receive a new token and give that a try
… And Oh là là! My script started working again! 🙂 Of course as I continued to add more functionality and test my script I ran back into the same error but this time I knew exactly how to resolve it.
So I registered for a third account (to yet again generate a new token ). FortunateIy, I completed my weekend project. See attachments Plot2.png and Plot3.png for pretty graphs
Now that I could see the forest through the trees and it was off to the cloud! I anticipated that it would take me a full week to explore Azure VMs but it actually only took a fews to wrap my head around it..
So this left me chance to pivot again and this time to a Data Warehouse/ Data Lake solution built for the Cloud. Turning the forecast for the rest of the week to Snow.
Here is a summary of what I did this week:
Sunday:
Developed Pandas/Python Script in conjunction with iexfinance & matplotlib modules to build graphs to show historical price for MSFT for 2020 and comparison of MSFT vs INTC for Jan 2nd – April 3rd 2020
Monday: (Brief summary)
Followed previous steps to build the plumbing on Azure for my small SQL Server farm (See Previous status on AWS EC2 for more details)
Created Resource Group
Create Application Security Group
Created 6 small Windows VMs in the same Region and an Availability Zone
Joined them to Windows domain
Tuesday: (Brief summary)
Created Windows Failover Cluster
Installed SQL Server 2016
Setup and configured AlwaysOn AGs and Listeners
Observations with Azure VMs:
Cons
Azure VMS are very slow first time brought up after build
Azure VMS has a longer provisioning time than EC2 Instances
No UI option to perform bulk tasks (like AWS UI) . Only option is Templating thru scripting
Can not move Resource Group from one Geographical location to another like VMs and other objects within Azure
When deleting a VM all child dependencies are not dropped ( Security Groups, NICs, Disks) – Perhaps this is by design?
– Objects need to be dissociated with groups and then deleted for clean up of orphan objects
Neutral
Easy to migrate VMs to higher T-Shirt Sizes
Easy to provision Storage Volumes per VM
Application Security Groups can be used to manage TCP/UDP traffic for entire resource group
Pros
You can migrate existing storage volumes to premium or cheaper storage seamlessly
Less network administration
less TCP/UDP ports need to be opened especially ports native to Windows domains
Very Easy to build Windows Failover clustering services
Natively works in the same subnet
Less configuration to get Connectivity to working then AWS EC2
Very Easy to configure SQL Server 2016 Always On
No need to create 5 Listeners (different per subnet) for a given specific AG
1 Listener per AG
Free Cost, Performance, Operation Excellence Recommendations Pop up after Login
Wednesday:
Registered for an Eval account for Snowflake instance
Attended Zero to Snowflake in 90 Minutes virtual Lab
Created Databases, Data Warehouses, User accounts, and Roles
Created Stages to be used for Data Import
Imported Data Sources (Data in S3 Buckets, CSV, JSON formats) via Web UI and SnowSQL cmd line tool
Ran various ANSI-92 T-SQL Queries to generate reports from SnowFlake
Developed a Pandas/Python Script using snowflake.connector & matplotlib modules to build a graph to show Citibike total rides over 12 month period (in descending order by rides per month) . See attachment plot.png