Week of June 12th

“Count to infinity, ones and zeroes”
Happy Russia 🇷🇺 Day !
Earth🌎 below us, Drifting, falling, Floating, weightless, Coming, coming home
After spending the previous two weeks in the far reaches 🚀 of space 🌌 , it was time 🕰 to return to my normal sphere of activity and back to the more familiar data realm. This week we took a journey into Google’s Data Warehouse solution better known as BigQuery🔎. This was our third go around in GCP as we previously looked at Google’s Compute and Data messaging service Pub/Sub.
It seems to me like the more we dive into the Google Cloud Platform ecosystem the more impressed we become with the GCP offerings. As for Data Warehouse, we had previously visited with Snowflake❄️ which we found to be a nifty SaaS solution for DW. After tinkering around a bit with BigQuery🔎 we found it to be equally utilitarian. BigQuery🔎 like its strong competitor offers a “No-Ops” approach to data warehousing while adhering to the 3Vs of Big Data. Although we didn’t benchmark either DW solution both offerings are highly performant based on 99 TPC-DS industry benchmarks
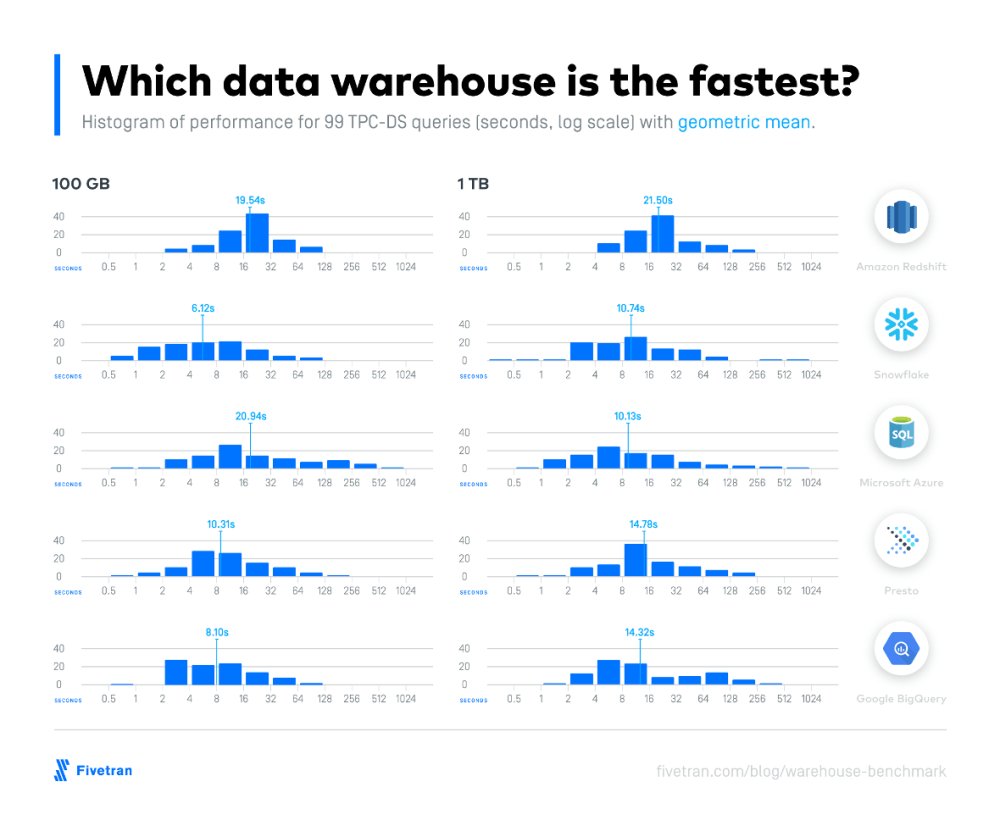
In the case of Snowflake❄️, it offers the flexibility to data professionals to scale the compute and storage resources up and down independently based on workloads whereas BigQuery 🔎 is “server-less” and all scaling is done automatically . BigQuery🔎 doesn’t use indexes but rather it relies on its awesome clustering technology to make its queries scream 💥.
Both Snowflake❄️ and BigQuery🔎 are quite similar with their low maintenance and minimal task administration but where both products make your head spin🌪 is trying to make heads or tails out of their pricing models. Snowflake’s❄️ pricing is a little bit easier to try to interrupt whereas BigQuery🔎 seems like you need to have P.H.D. in cost models just to read through the fine print.
To accurately determine which product, offers a better TCO, really depends on your individual workloads. From what I gather if you’re running lots of queries sporadically, with high idle time than BigQuery🔎 is the place to be from a pricing standpoint. However, if your workloads are more consistent than its probably more cost effective to go with Snowflake❄️ based on their pay as you go model.
To assist us on our exploration of BigQuery was the founder of LoonyCorn, the bright and talented Janani Ravi through her excellent Pluralsight course. Janani gives a great overview of the solution and keeps the flow of the course at a reasonable pace as we took a deep dive into this complex data technology.
One Interesting observations about the course as it was published about a year and half ago (15 Oct 2018) is how much improvements Google has made to the product offering since then including a refined UI, more options for partition keys and enhancements to Python Module. The course touches on design, comparison to RDBMS, and other DWs and shows us different ingestion of file types including the popular Binary format Avaro.
The meat🥩 and potatoes🥔 of the course is the section of Programmatically Accessing BigQuery from Client Programs. This is where Jani goes into some advanced programming options like UNNEST, ARRAY_AGG, STRUCT Operators and the powerful Windowing Operations.
See log for more details
To round out the course, she takes us through some additional nuggets in GCP like Google Data Studio (https://datastudio.google.com/) for Data Visualization and Cloud☁️ Notebooks📓 and Python by utilizing Google Datalab🧪.
Stay, ahhh Just a little bit longer Please, please, please, please, please Tell me that you’re going to….
Below are some topics I am considering for my travels next week:
- Google Cloud Data Fusion (EL/ETL/ELT)
- More on Google Big Query
- More on Data Pipelines
- NoSQL – MongoDB, Cosmos DB
- Working JSON Files
- Working with Parquet files
- JDBC Drivers
- More on Machine Learning
- ONTAP Cluster Fundamentals
- Data Visualization Tools (i.e. Looker)
- ETL Solutions (Stitch, FiveTran)
- Process and Transforming data/Explore data through ML (i.e. Databricks)
Stay safe and Be well –
–MCS



